#方式一: SELECT salary FROM employees WHERE last_name ='Abel'; SELECT last_name,salary FROM employees WHERE salary >11000; #方式二:自连接 SELECT e2.last_name,e2.salary FROM employees e1,employees e2 WHERE e1.last_name ='Abel' AND e1.`salary` < e2.`salary`
#方式三:子查询 SELECT last_name,salary FROM employees WHERE salary > ( SELECT salary FROM employees WHERE last_name ='Abel' );
SELECT last_name, job_id, salary FROM employees WHERE job_id = (SELECT job_id FROM employees WHERE employee_id =141) AND salary > (SELECT salary FROM employees WHERE employee_id =143);
SELECT employee_id, manager_id, department_id FROM employees WHERE manager_id IN (SELECT manager_id FROM employees WHERE employee_id IN (174,141)) AND department_id IN (SELECT department_id FROM employees WHERE employee_id IN (174,141)) AND employee_id NOTIN(174,141);
实现方式2:成对比较
1 2 3 4 5 6 7
SELECT employee_id, manager_id, department_id FROM employees WHERE (manager_id, department_id) IN (SELECT manager_id, department_id FROM employees WHERE employee_id IN (141,174)) AND employee_id NOTIN (141,174);
2.3 HAVING 中的子查询
首先执行子查询。
向主查询中的HAVING 子句返回结果。
题目:查询最低工资大于50号部门最低工资的部门id和其最低工资
1 2 3 4 5 6 7
SELECT department_id, MIN(salary) FROM employees GROUPBY department_id HAVINGMIN(salary) > (SELECTMIN(salary) FROM employees WHERE department_id =50);
SELECT employee_id, last_name, (CASE department_id WHEN (SELECT department_id FROM departments WHERE location_id =1800) THEN'Canada'ELSE'USA'END) location FROM employees;
2.5 子查询中的空值问题
1 2 3 4 5 6 7 8
SELECT last_name, job_id FROM employees WHERE job_id = (SELECT job_id FROM employees WHERE last_name ='Haas'); # Emptyset (0.00 sec) #子查询不返回任何行
2.5 非法使用子查询
1 2 3 4 5 6 7
SELECT employee_id, last_name FROM employees WHERE salary = (SELECTMIN(salary) FROM employees GROUPBY department_id); #多行子查询使用单行比较符
#方式2:了解 SELECT employee_id,manager_id,department_id FROM employees WHERE (manager_id,department_id) = ( SELECT manager_id,department_id FROM employees WHERE employee_id =141 ) AND employee_id <>141;
#题目:显式员工的employee_id,last_name和location。 #其中,若员工department_id与location_id为1800的department_id相同, #则location为’Canada’,其余则为’USA’。 SELECT employee_id,last_name,CASE department_id WHEN (SELECT department_id FROM departments WHERE location_id =1800) THEN'Canada' ELSE'USA'END "location" FROM employees; /*部分输出 107行 +-------------+-------------+----------+ | employee_id | last_name | location | +-------------+-------------+----------+ | 100 | King | USA | | 101 | Kochhar | USA | | 102 | De Haan | USA | | 103 | Hunold | USA | | 104 | Ernst | USA | | 105 | Austin | USA | | 106 | Pataballa | USA | */
#4.2 子查询中的空值问题 SELECT last_name, job_id FROM employees WHERE job_id = (SELECT job_id FROM employees WHERE last_name ='Haas');#员工中没有Haas #4.3 非法使用子查询 #错误:Subquery returns more than 1row SELECT employee_id, last_name FROM employees WHERE salary = (SELECTMIN(salary) FROM employees GROUPBY department_id);#返回值不止一个,不能用等号连接
题目:查询员工中工资大于本部门平均工资的员工的last_name,salary和其department_id 方式一:相关子查询 方式二:在 FROM 中使用子查询
1 2 3 4
SELECT last_name,salary,e1.department_id FROM employees e1,(SELECT department_id,AVG(salary) dept_avg_sal FROM employees GROUPBY department_id) e2 WHERE e1.`department_id` = e2.department_id AND e2.dept_avg_sal < e1.`salary`;
#题目:查询员工的id,salary,按照department_name 排序 SELECT employee_id,salary FROM employees e ORDERBY ( SELECT department_name FROM departments d WHERE e.`department_id` = d.`department_id` ) ASC; /* +-------------+----------+ | employee_id | salary | +-------------+----------+ | 178 | 7000.00 | | 205 | 12000.00 | | 206 | 8300.00 | | 200 | 4400.00 | */
#结论:在SELECT中,除了GROUPBY 和 LIMIT之外,其他位置都可以声明子查询! /* SELECT ....,....,....(存在聚合函数) FROM ... (LEFT / RIGHT)JOIN ....ON 多表的连接条件 (LEFT / RIGHT)JOIN ... ON .... WHERE 不包含聚合函数的过滤条件 GROUP BY ...,.... HAVING 包含聚合函数的过滤条件 ORDER BY ....,...(ASC / DESC ) LIMIT ...,.... */
# 第09章_子查询的课后练习 #1.查询和Zlotkey相同部门的员工姓名和工资 SELECT last_name,salary FROM employees WHERE department_id IN ( SELECT department_id FROM employees WHERE last_name ='Zlotkey' );
#2.查询工资比公司平均工资高的员工的员工号,姓名和工资。 SELECT employee_id,last_name,salary FROM employees WHERE salary > ( SELECTAVG(salary) FROM employees );
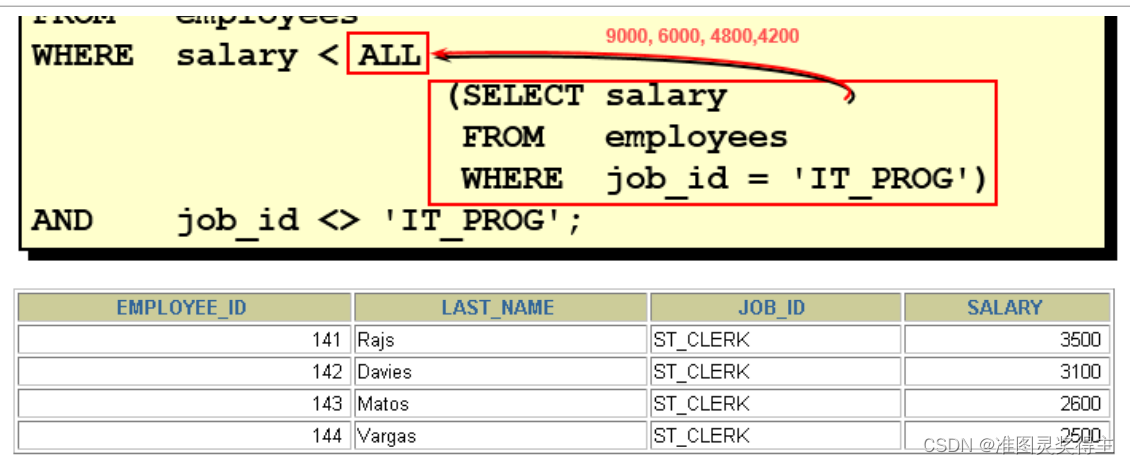
#3.选择工资大于所有JOB_ID ='SA_MAN'的员工的工资的员工的last_name, job_id, salary SELECT last_name,job_id,salary FROM employees WHERE salary >ALL( SELECT salary FROM employees WHERE job_id ='SA_MAN' );
#4.查询和姓名中包含字母u的员工在相同部门的员工的员工号和姓名 SELECT employee_id,last_name FROM employees WHERE department_id IN ( SELECTDISTINCT department_id FROM employees WHERE last_name LIKE'%u%' );
#5.查询在部门的location_id为1700的部门工作的员工的员工号 SELECT employee_id FROM employees WHERE department_id IN ( SELECT department_id FROM departments WHERE location_id =1700 );
#6.查询管理者是King的员工姓名和工资 SELECT last_name,salary,manager_id FROM employees WHERE manager_id IN ( SELECT employee_id FROM employees WHERE last_name ='King' );
#7.查询工资最低的员工信息: last_name, salary SELECT last_name,salary FROM employees WHERE salary = ( SELECTMIN(salary) FROM employees );
#8.查询平均工资最低的部门信息 #方式1: SELECT* FROM departments WHERE department_id = ( SELECT department_id FROM employees GROUPBY department_id HAVINGAVG(salary ) = ( SELECTMIN(avg_sal) FROM ( SELECTAVG(salary) avg_sal FROM employees GROUPBY department_id ) t_dept_avg_sal
) ); #方式2:ALL SELECT* FROM departments WHERE department_id = ( SELECT department_id FROM employees GROUPBY department_id HAVINGAVG(salary ) <=ALL( SELECTAVG(salary) FROM employees GROUPBY department_id ) );
#方式3: LIMIT
SELECT* FROM departments WHERE department_id = ( SELECT department_id FROM employees GROUPBY department_id HAVINGAVG(salary ) =( SELECTAVG(salary) avg_sal FROM employees GROUPBY department_id ORDERBY avg_sal ASC LIMIT 1 ) );
#方式4: SELECT d.* FROM departments d,( SELECT department_id,AVG(salary) avg_sal FROM employees GROUPBY department_id ORDERBY avg_sal ASC LIMIT 0,1 ) t_dept_avg_sal WHERE d.`department_id` = t_dept_avg_sal.department_id
#9.查询平均工资最低的部门信息和该部门的平均工资(相关子查询) #方式1: SELECT d.*,(SELECTAVG(salary) FROM employees WHERE department_id = d.`department_id`) avg_sal FROM departments d WHERE department_id = ( SELECT department_id FROM employees GROUPBY department_id HAVINGAVG(salary ) = ( SELECTMIN(avg_sal) FROM ( SELECTAVG(salary) avg_sal FROM employees GROUPBY department_id ) t_dept_avg_sal
) );
#方式2:
SELECT d.*,(SELECTAVG(salary) FROM employees WHERE department_id = d.`department_id`) avg_sal FROM departments d WHERE department_id = ( SELECT department_id FROM employees GROUPBY department_id HAVINGAVG(salary ) <=ALL( SELECTAVG(salary) FROM employees GROUPBY department_id ) );
#方式3: LIMIT
SELECT d.*,(SELECTAVG(salary) FROM employees WHERE department_id = d.`department_id`) avg_sal FROM departments d WHERE department_id = ( SELECT department_id FROM employees GROUPBY department_id HAVINGAVG(salary ) =( SELECTAVG(salary) avg_sal FROM employees GROUPBY department_id ORDERBY avg_sal ASC LIMIT 1 ) );
#方式4:
SELECT d.*,(SELECTAVG(salary) FROM employees WHERE department_id = d.`department_id`) avg_sal FROM departments d,( SELECT department_id,AVG(salary) avg_sal FROM employees GROUPBY department_id ORDERBY avg_sal ASC LIMIT 0,1 ) t_dept_avg_sal WHERE d.`department_id` = t_dept_avg_sal.department_id
#10.查询平均工资最高的 job 信息 #方式1: SELECT* FROM jobs WHERE job_id = ( SELECT job_id FROM employees GROUPBY job_id HAVINGAVG(salary) = ( SELECTMAX(avg_sal) FROM ( SELECTAVG(salary) avg_sal FROM employees GROUPBY job_id ) t_job_avg_sal ) );
#方式2: SELECT* FROM jobs WHERE job_id = ( SELECT job_id FROM employees GROUPBY job_id HAVINGAVG(salary) >=ALL( SELECTAVG(salary) FROM employees GROUPBY job_id ) );
#方式3: SELECT* FROM jobs WHERE job_id = ( SELECT job_id FROM employees GROUPBY job_id HAVINGAVG(salary) =( SELECTAVG(salary) avg_sal FROM employees GROUPBY job_id ORDERBY avg_sal DESC LIMIT 0,1 ) );
#方式4: SELECT j.* FROM jobs j,( SELECT job_id,AVG(salary) avg_sal FROM employees GROUPBY job_id ORDERBY avg_sal DESC LIMIT 0,1 ) t_job_avg_sal WHERE j.job_id = t_job_avg_sal.job_id
#11.查询平均工资高于公司平均工资的部门有哪些? SELECT department_id FROM employees WHERE department_id ISNOT NULL GROUPBY department_id HAVINGAVG(salary) > ( SELECTAVG(salary) FROM employees );
#12.查询出公司中所有 manager 的详细信息
#方式1:自连接 xxx worked for yyy SELECTDISTINCT mgr.employee_id,mgr.last_name,mgr.job_id,mgr.department_id FROM employees emp JOIN employees mgr ON emp.manager_id = mgr.employee_id;
#方式2:子查询
SELECT employee_id,last_name,job_id,department_id FROM employees WHERE employee_id IN ( SELECTDISTINCT manager_id FROM employees );
#方式3:使用EXISTS SELECT employee_id,last_name,job_id,department_id FROM employees e1 WHEREEXISTS ( SELECT* FROM employees e2 WHERE e1.`employee_id` = e2.`manager_id` );
#13.各个部门中 最高工资中最低的那个部门的 最低工资是多少?
#方式1: SELECTMIN(salary) FROM employees WHERE department_id = ( SELECT department_id FROM employees GROUPBY department_id HAVINGMAX(salary) = ( SELECTMIN(max_sal) FROM ( SELECTMAX(salary) max_sal FROM employees GROUPBY department_id ) t_dept_max_sal ) );
SELECT* FROM employees WHERE department_id =10;
#方式2: SELECTMIN(salary) FROM employees WHERE department_id = ( SELECT department_id FROM employees GROUPBY department_id HAVINGMAX(salary) <=ALL ( SELECTMAX(salary) FROM employees GROUPBY department_id ) );
#方式3: SELECTMIN(salary) FROM employees WHERE department_id = ( SELECT department_id FROM employees GROUPBY department_id HAVINGMAX(salary) = ( SELECTMAX(salary) max_sal FROM employees GROUPBY department_id ORDERBY max_sal ASC LIMIT 0,1 ) ); #方式4: SELECTMIN(salary) FROM employees e,( SELECT department_id,MAX(salary) max_sal FROM employees GROUPBY department_id ORDERBY max_sal ASC LIMIT 0,1 ) t_dept_max_sal WHERE e.department_id = t_dept_max_sal.department_id
#14.查询平均工资最高的部门的 manager 的详细信息: last_name, department_id, email, salary #方式1: SELECT last_name, department_id, email, salary FROM employees WHERE employee_id =ANY ( SELECTDISTINCT manager_id FROM employees WHERE department_id = ( SELECT department_id FROM employees GROUPBY department_id HAVINGAVG(salary) = ( SELECTMAX(avg_sal) FROM ( SELECTAVG(salary) avg_sal FROM employees GROUPBY department_id ) t_dept_avg_sal ) ) );
#方式2: SELECT last_name, department_id, email, salary FROM employees WHERE employee_id =ANY ( SELECTDISTINCT manager_id FROM employees WHERE department_id = ( SELECT department_id FROM employees GROUPBY department_id HAVINGAVG(salary) >=ALL ( SELECTAVG(salary) avg_sal FROM employees GROUPBY department_id ) ) );
#方式3: SELECT last_name, department_id, email, salary FROM employees WHERE employee_id IN ( SELECTDISTINCT manager_id FROM employees e,( SELECT department_id,AVG(salary) avg_sal FROM employees GROUPBY department_id ORDERBY avg_sal DESC LIMIT 0,1 ) t_dept_avg_sal WHERE e.`department_id` = t_dept_avg_sal.department_id );
#15. 查询部门的部门号,其中不包括job_id是"ST_CLERK"的部门号 #方式1: SELECT department_id FROM departments WHERE department_id NOTIN ( SELECTDISTINCT department_id FROM employees WHERE job_id ='ST_CLERK' );
#方式2: SELECT department_id FROM departments d WHERENOTEXISTS ( SELECT* FROM employees e WHERE d.`department_id` = e.`department_id` AND e.`job_id` ='ST_CLERK' );
#16. 选择所有没有管理者的员工的last_name
SELECT last_name FROM employees emp WHERENOTEXISTS ( SELECT* FROM employees mgr WHERE emp.`manager_id` = mgr.`employee_id` );
#17.查询员工号、姓名、雇用时间、工资,其中员工的管理者为 'De Haan' #方式1: SELECT employee_id,last_name,hire_date,salary FROM employees WHERE manager_id IN ( SELECT employee_id FROM employees WHERE last_name ='De Haan' );
#方式2: SELECT employee_id,last_name,hire_date,salary FROM employees e1 WHEREEXISTS ( SELECT* FROM employees e2 WHERE e1.`manager_id` = e2.`employee_id` AND e2.last_name ='De Haan' );
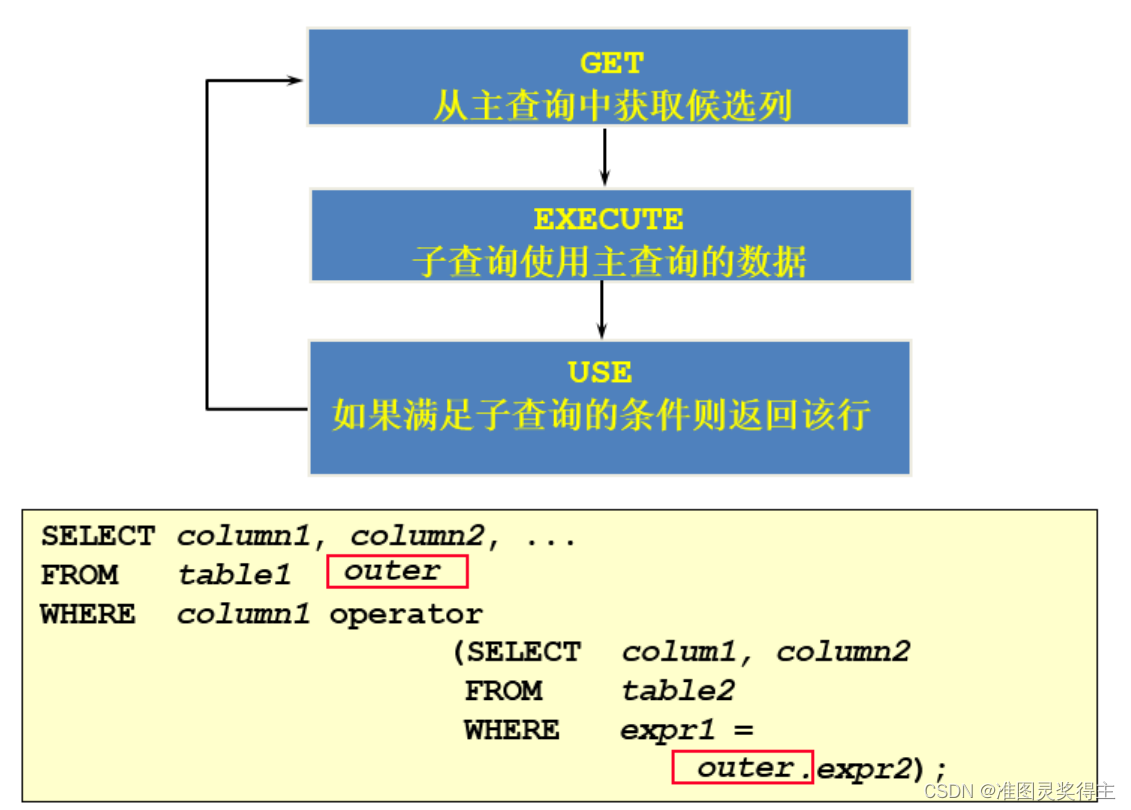
#18.查询各部门中工资比本部门平均工资高的员工的员工号, 姓名和工资(相关子查询) #方式1:使用相关子查询 SELECT last_name,salary,department_id FROM employees e1 WHERE salary > ( SELECTAVG(salary) FROM employees e2 WHERE department_id = e1.`department_id` );
#方式2:在FROM中声明子查询 SELECT e.last_name,e.salary,e.department_id FROM employees e,( SELECT department_id,AVG(salary) avg_sal FROM employees GROUPBY department_id) t_dept_avg_sal WHERE e.department_id = t_dept_avg_sal.department_id AND e.salary > t_dept_avg_sal.avg_sal
#19.查询每个部门下的部门人数大于 5 的部门名称(相关子查询) SELECT department_name FROM departments d WHERE5< ( SELECTCOUNT(*) FROM employees e WHERE d.department_id = e.`department_id` );




 微信
微信 支付宝
支付宝









