泰坦尼克号生存的预测任务 学校作业,我来水一水
环境:pycharm+anaconda虚拟环境
0.环境搭建参考: 学校机器学习_为了前进而后退,为了走直路而走弯路的博客-CSDN博客
1 目的与要求 (1)目的: 本任务旨在使用机器学习算法预测泰坦尼克号乘客的生存情况。根据乘客的个人信息(如年龄、性别、船舱等级等),使用合适的模型来判断该乘客是否在事故中幸存。模型将对给定的测试集进行预测,并生成预测结果。
2 任务背景 泰坦尼克号(RMS Titanic)是世界历史上最著名的沉船之一,1912年4月15日沉没。在事故中,约有1500多人失去了生命。根据该事件的相关数据集(包含乘客的个人信息及生死状态),我们可以构建模型预测乘客的生存概率。数据集包含的特征有:乘客的年龄、性别、船舱等级、票价、家庭成员数量等。
3 任务简介 数据集介绍:
**目标:**构建机器学习模型,预测乘客在事故中是否生还(分类任务)。
**处理缺失值:**填充年龄的缺失值为平均值,填充 Embarked 的缺失值为众数,填充 Fare 的缺失值为均值。
特征工程:将性别特征(Sex)从字符型转化为数值型(男为0,女为1)。
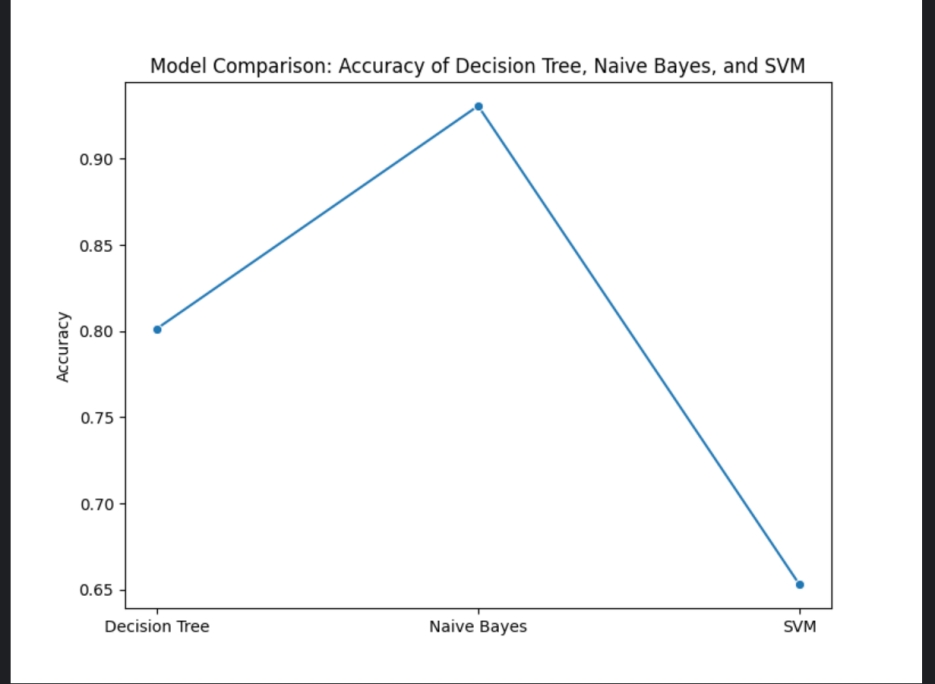
任务目标:通过不同的机器学习算法(如决策树、朴素贝叶斯、支持向量机),对乘客生还与否进行预测,并比较其准确率。
可视化图表
准确率对比折线图:
4 模型介绍
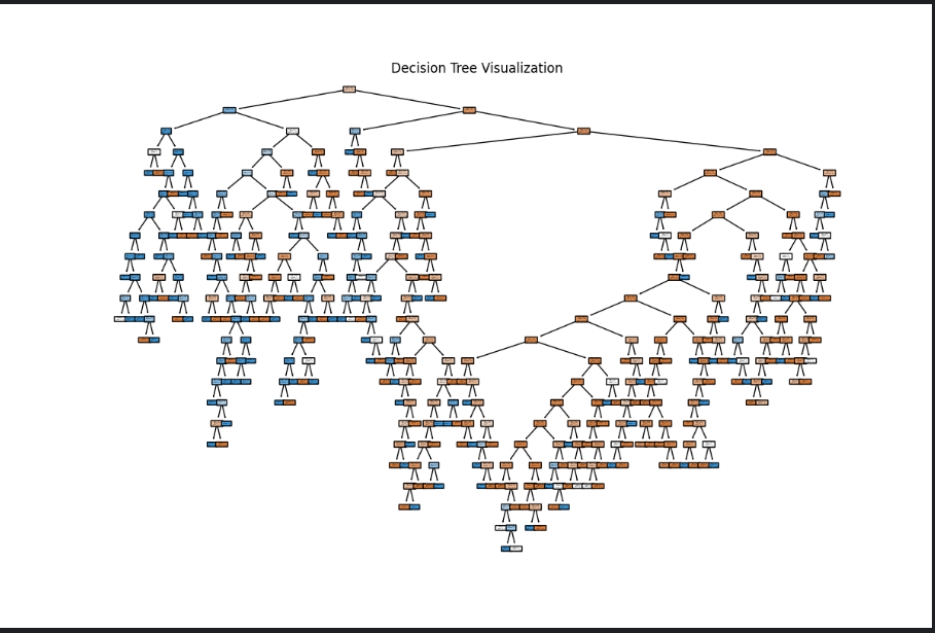
1.决策树(Decision Tree) 简介:决策树是一种树形结构的模型,适用于分类和回归任务。它通过一系列的决策规则将数据划分为不同的类别,直到满足某种停止条件。决策树模型易于理解和解释。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 关键代码: from sklearn.tree import DecisionTreeClassifier, plot_tree决策树模型训练 dt_model = DecisionTreeClassifier(random_state=42 ) dt_model.fit(X_train, y_train) 预测 dt_y_pred = dt_model.predict(X_test) 绘制决策树图 plt.figure(figsize=(12 , 8 )) plot_tree(dt_model, feature_names=features, class_names=['Not Survived' , 'Survived' ], filled=True , rounded=True ) plt.title("Decision Tree Visualization" ) plt.savefig('decision_tree.png' )
**模型评估:**通过 accuracy_score 计算准确率,比较实际与预测结果。
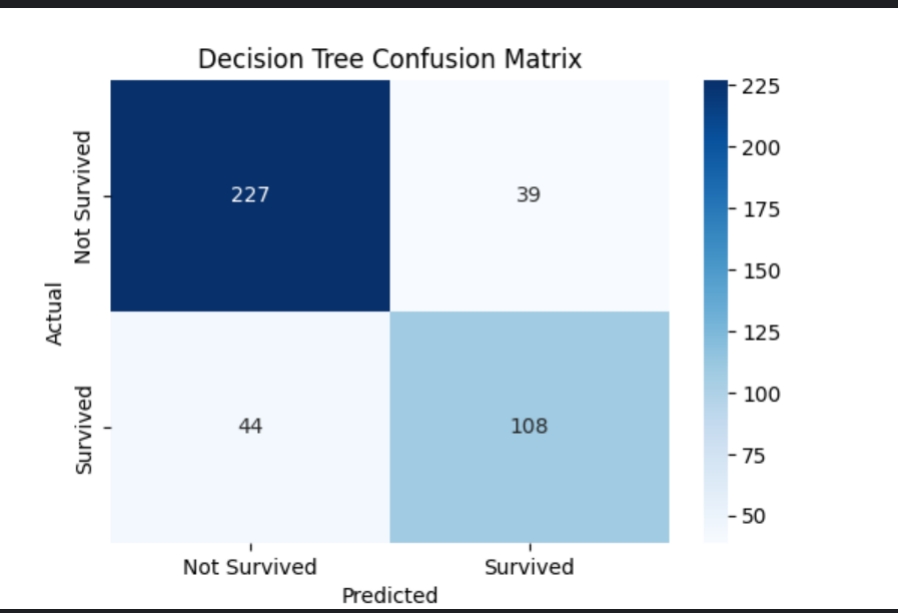
结果:准确率:0.8014
decision_tree.png
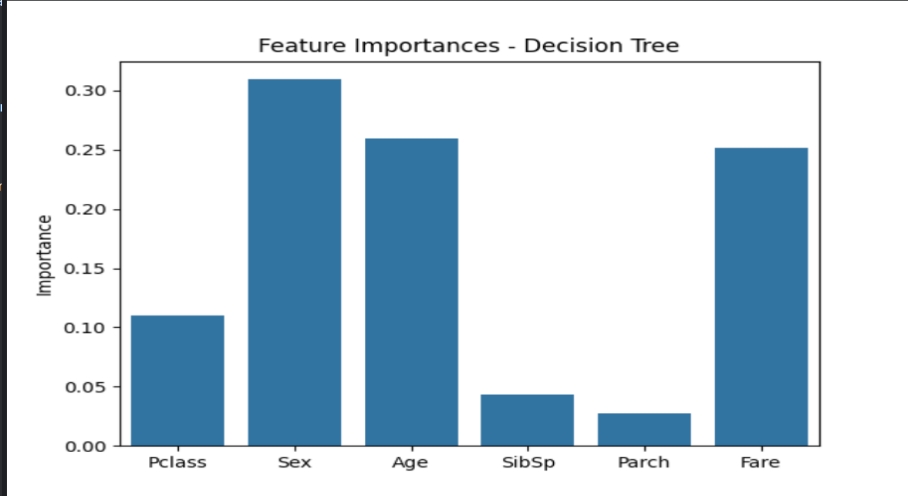
feature_importance.png
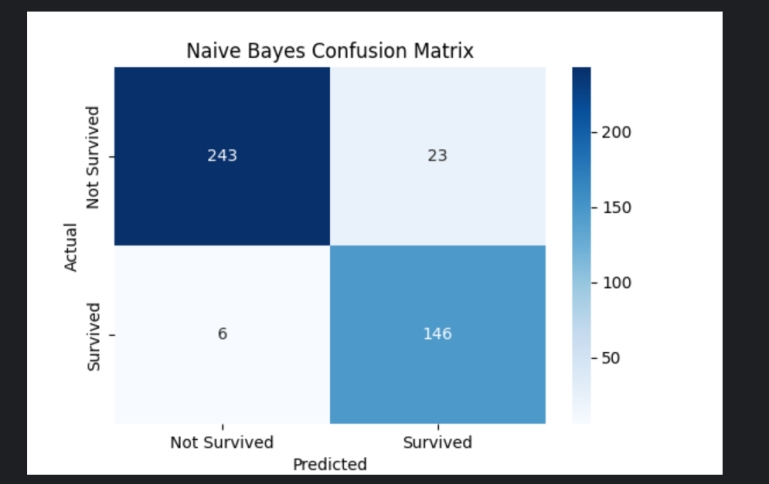
2.朴素贝叶斯(Naive Bayes) 简介:朴素贝叶斯是一种基于贝叶斯定理的分类算法,适用于特征之间独立性假设成立的场景。它通过计算各类别的条件概率,选择概率最大的类别作为预测结果。
1 2 3 4 5 6 7 8 9 10 11 12 关键代码: from sklearn.naive_bayes import GaussianNB朴素贝叶斯模型训练 nb_model = GaussianNB() nb_model.fit(X_train, y_train) 预测 nb_y_pred = nb_model.predict(X_test) 模型评估:同样使用 accuracy_score 来评估朴素贝叶斯模型的准确率。
结果:
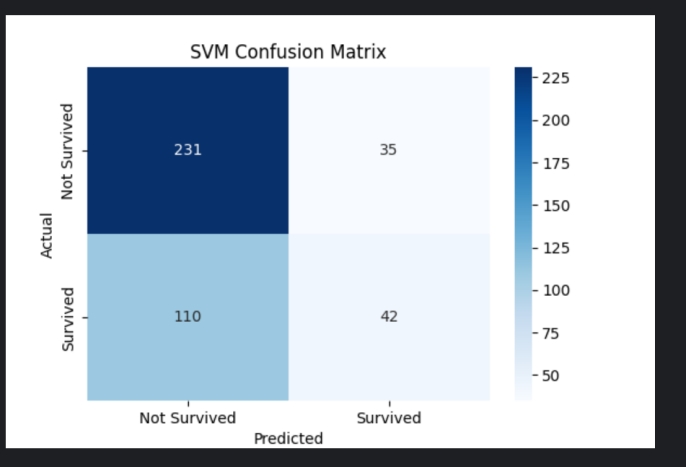
3.支持向量机(Support Vector Machine, SVM) 简介:支持向量机是一种基于最大间隔原则的分类模型,主要用于二分类问题。SVM通过构造一个超平面来实现分类,使得不同类别的数据点距离超平面尽可能远。
1 2 3 4 5 6 7 8 9 10 11 关键代码: from sklearn.svm import SVC支持向量机模型训练 svm_model = SVC(random_state=42 ) svm_model.fit(X_train, y_train) 预测 svm_y_pred = svm_model.predict(X_test)
模型评估:使用 accuracy_score 来评估SVM模型的准确率。
代码示例:
绘制模型准确率折线图
1 2 3 4 5 6 7 accuracies = [dt_accuracy, nb_accuracy, svm_accuracy] models = ['Decision Tree', 'Naive Bayes', 'SVM'] sns.lineplot(x=models, y=accuracies, marker='o') plt.title('Model Comparison: Accuracy of Decision Tree, Naive Bayes, and SVM') plt.ylabel('Accuracy') plt.savefig('model_comparison_accuracy.png') plt.show()
结果:
完整代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsimport osfrom sklearn.model_selection import train_test_splitfrom sklearn.tree import DecisionTreeClassifier, plot_treefrom sklearn.naive_bayes import GaussianNBfrom sklearn.svm import SVCfrom sklearn.metrics import accuracy_score, confusion_matrixfrom sklearn.preprocessing import LabelEncodertrain_df = pd.read_csv('mytrain.csv' ) test_df = pd.read_csv('mytest.csv' ) gender_df = pd.read_csv('mygender.csv' ) train_df.fillna({'Age' : train_df['Age' ].mean(), 'Embarked' : train_df['Embarked' ].mode()[0 ]}, inplace=True ) test_df.fillna({'Age' : test_df['Age' ].mean(), 'Fare' : test_df['Fare' ].mean()}, inplace=True ) label_encoder = LabelEncoder() train_df['Sex' ] = label_encoder.fit_transform(train_df['Sex' ]) test_df['Sex' ] = label_encoder.transform(test_df['Sex' ]) features = ['Pclass' , 'Sex' , 'Age' , 'SibSp' , 'Parch' , 'Fare' ] X_train = train_df[features] y_train = train_df['Survived' ] X_test = test_df[features] def create_folder (folder_name ): if not os.path.exists(folder_name): os.makedirs(folder_name) accuracies = [] dt_model = DecisionTreeClassifier(random_state=42 ) dt_model.fit(X_train, y_train) dt_y_pred = dt_model.predict(X_test) dt_accuracy = accuracy_score(gender_df['Survived' ], dt_y_pred) accuracies.append(dt_accuracy) nb_model = GaussianNB() nb_model.fit(X_train, y_train) nb_y_pred = nb_model.predict(X_test) nb_accuracy = accuracy_score(gender_df['Survived' ], nb_y_pred) accuracies.append(nb_accuracy) svm_model = SVC(random_state=42 ) svm_model.fit(X_train, y_train) svm_y_pred = svm_model.predict(X_test) svm_accuracy = accuracy_score(gender_df['Survived' ], svm_y_pred) accuracies.append(svm_accuracy) def visualize_decision_tree (model, folder_name ): plt.figure(figsize=(12 , 8 )) plot_tree(model, feature_names=features, class_names=['Not Survived' , 'Survived' ], filled=True , rounded=True ) plt.title("Decision Tree Visualization" ) plt.savefig(os.path.join(folder_name, "decision_tree.png" )) plt.close() def visualize_confusion_matrix (y_true, y_pred, folder_name, model_name ): conf_matrix = confusion_matrix(y_true, y_pred) plt.figure(figsize=(6 , 4 )) sns.heatmap(conf_matrix, annot=True , fmt='d' , cmap='Blues' , xticklabels=['Not Survived' , 'Survived' ], yticklabels=['Not Survived' , 'Survived' ]) plt.title(f'{model_name} Confusion Matrix' ) plt.ylabel('Actual' ) plt.xlabel('Predicted' ) plt.savefig(os.path.join(folder_name, f"{model_name} _confusion_matrix.png" )) plt.close() def visualize_feature_importance (model, folder_name ): feature_importances = model.feature_importances_ sns.barplot(x=features, y=feature_importances) plt.title('Feature Importances - Decision Tree' ) plt.ylabel('Importance' ) plt.savefig(os.path.join(folder_name, "feature_importance.png" )) plt.close() dt_folder = 'decision_tree_results' create_folder(dt_folder) visualize_decision_tree(dt_model, dt_folder) visualize_confusion_matrix(gender_df['Survived' ], dt_y_pred, dt_folder, 'Decision Tree' ) visualize_feature_importance(dt_model, dt_folder) nb_folder = 'naive_bayes_results' create_folder(nb_folder) visualize_confusion_matrix(gender_df['Survived' ], nb_y_pred, nb_folder, 'Naive Bayes' ) svm_folder = 'svm_results' create_folder(svm_folder) visualize_confusion_matrix(gender_df['Survived' ], svm_y_pred, svm_folder, 'SVM' ) plt.figure(figsize=(8 , 6 )) models = ['Decision Tree' , 'Naive Bayes' , 'SVM' ] sns.lineplot(x=models, y=accuracies, marker='o' ) plt.title('Model Comparison: Accuracy of Decision Tree, Naive Bayes, and SVM' ) plt.ylabel('Accuracy' ) plt.savefig('model_comparison_accuracy.png' ) plt.show() print (f"Decision Tree Accuracy: {dt_accuracy:.4 f} " )print (f"Naive Bayes Accuracy: {nb_accuracy:.4 f} " )print (f"SVM Accuracy: {svm_accuracy:.4 f} " )
三种算法对比折线图:
5 结论 总结: 通过本次任务,我使用了三种不同的机器学习算法:决策树、朴素贝叶斯和支持向量机,来预测泰坦尼克号乘客的生还与否。每个算法都进行了训练并生成了相应的预测结果。通过对比准确率,我发现不同模型在本任务中的表现有所不同。
6.训练集测试集代码链接 我就直接把整个项目的都放在这了
通过网盘分享的文件:PythonProjecthttps://pan.baidu.com/s/1VXbp32N29owHKvdf7F0eoA 提取码: zp5u
 微信
微信 支付宝
支付宝






