深度学习与神经网络 | 邱锡鹏 | 第七章学习笔记 网络优化与正则化
7.网络优化与正则化
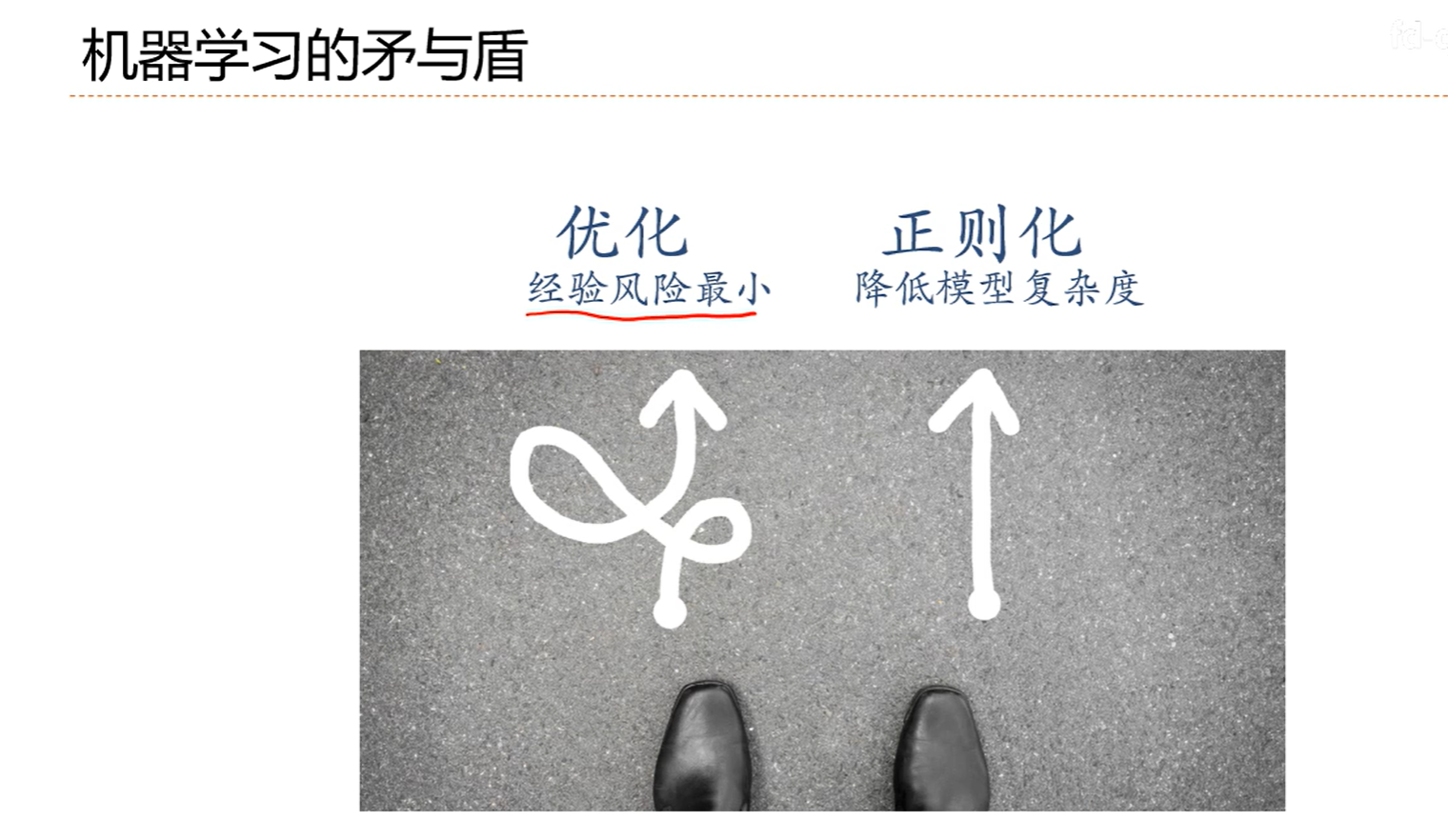

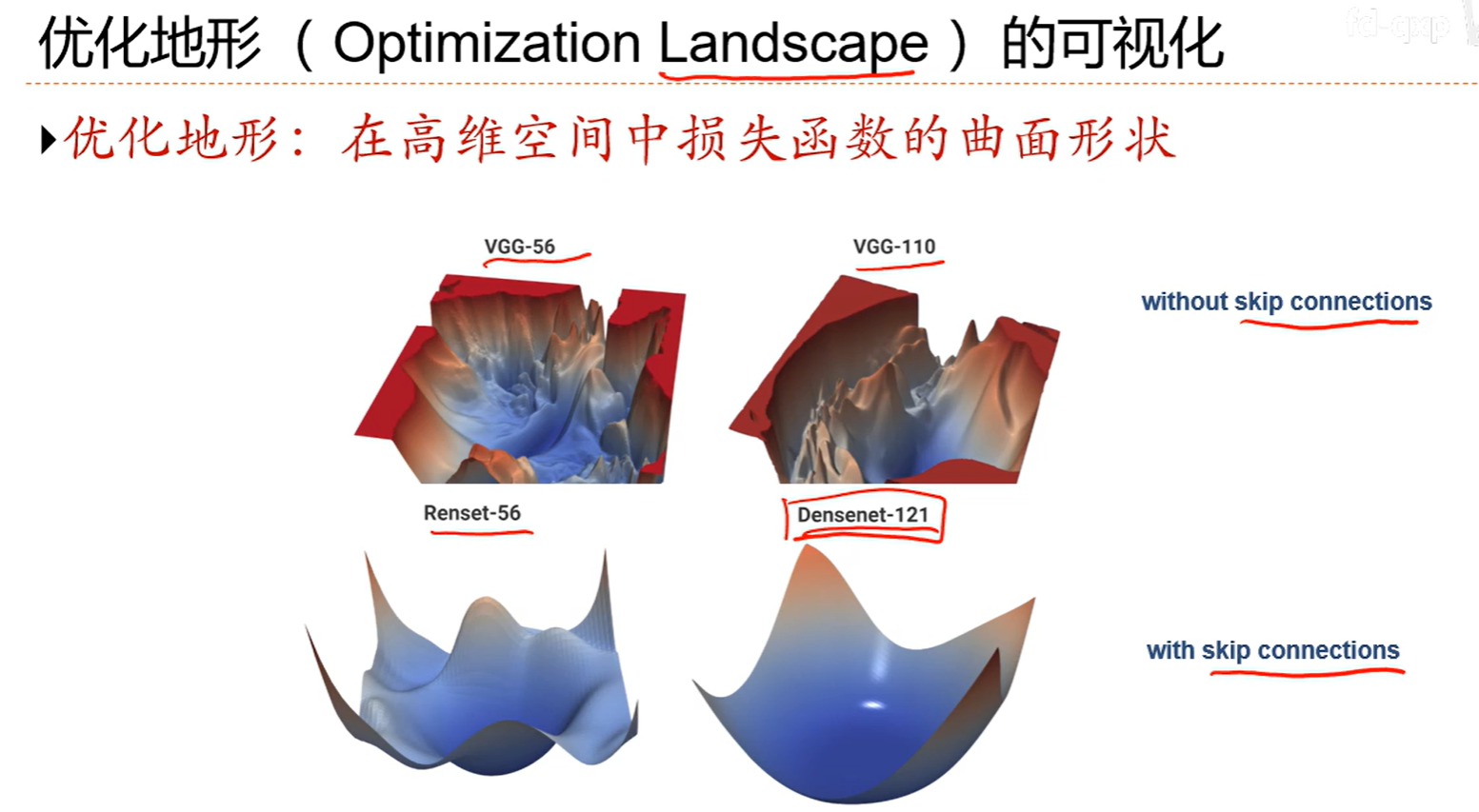
7.1神经网络优化的特点

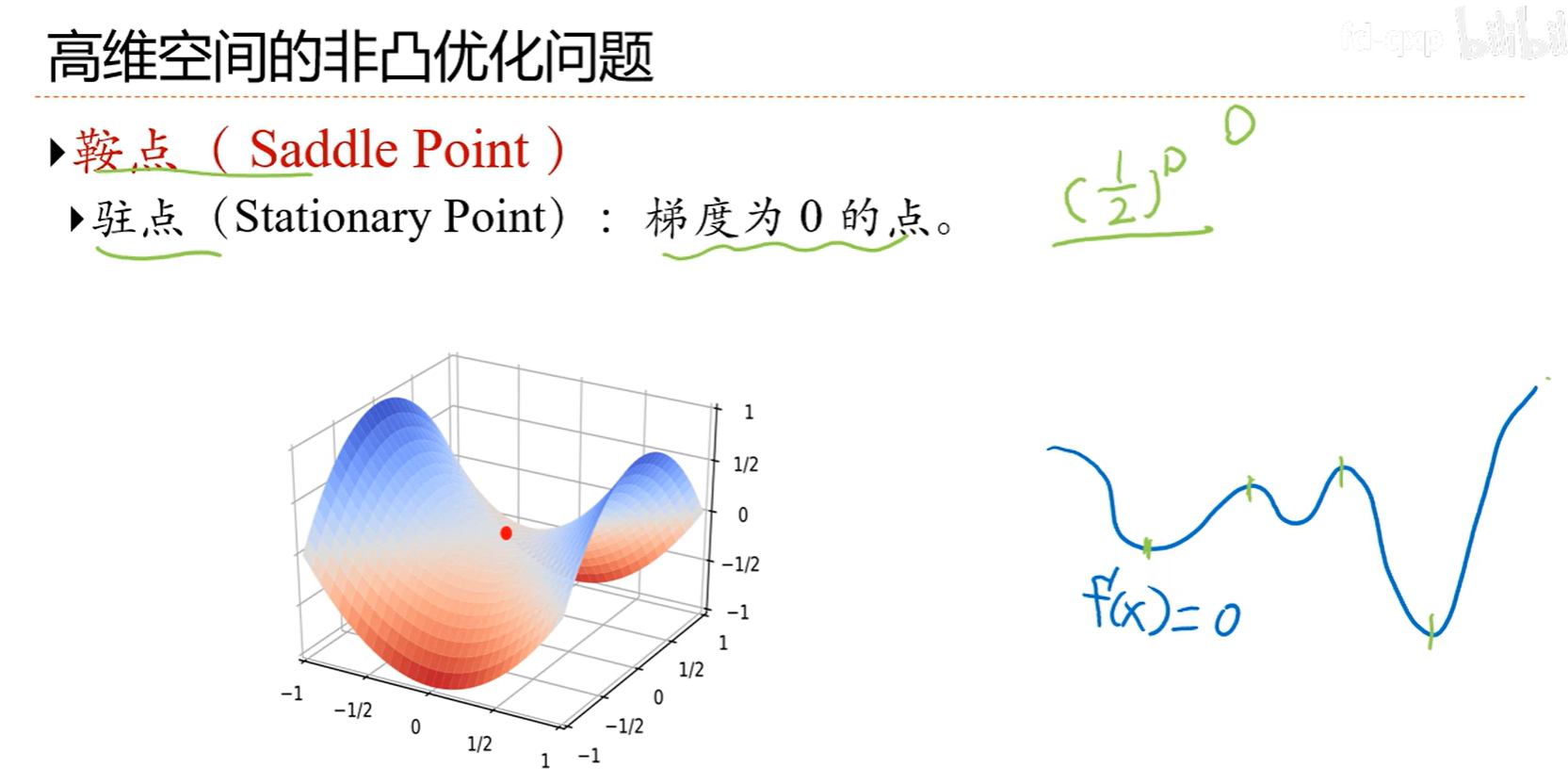

所以找个平坦最小值就好了,不一定需要全局最小值

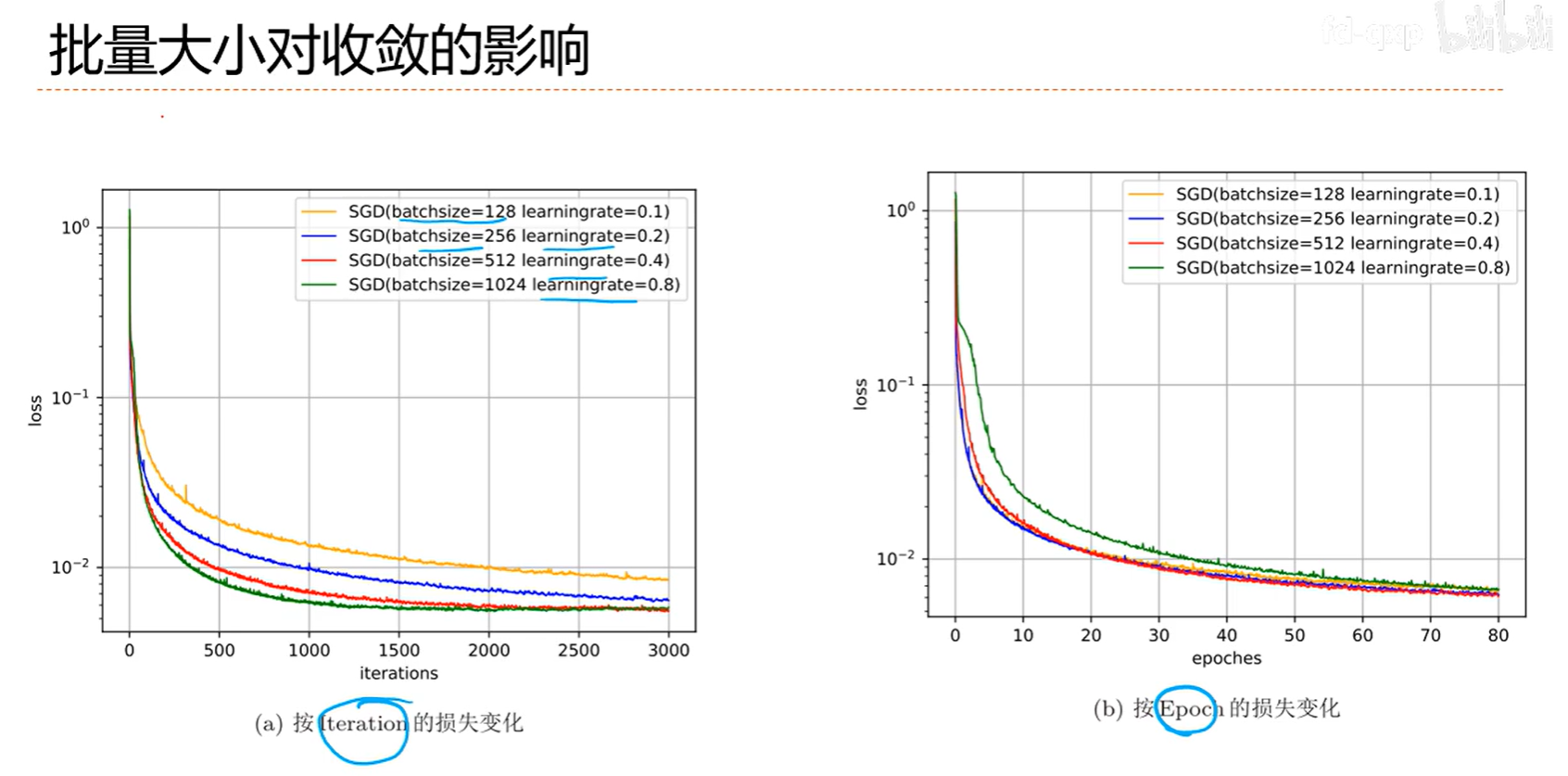
7.2 优化算法改进




7.3 动态学习率
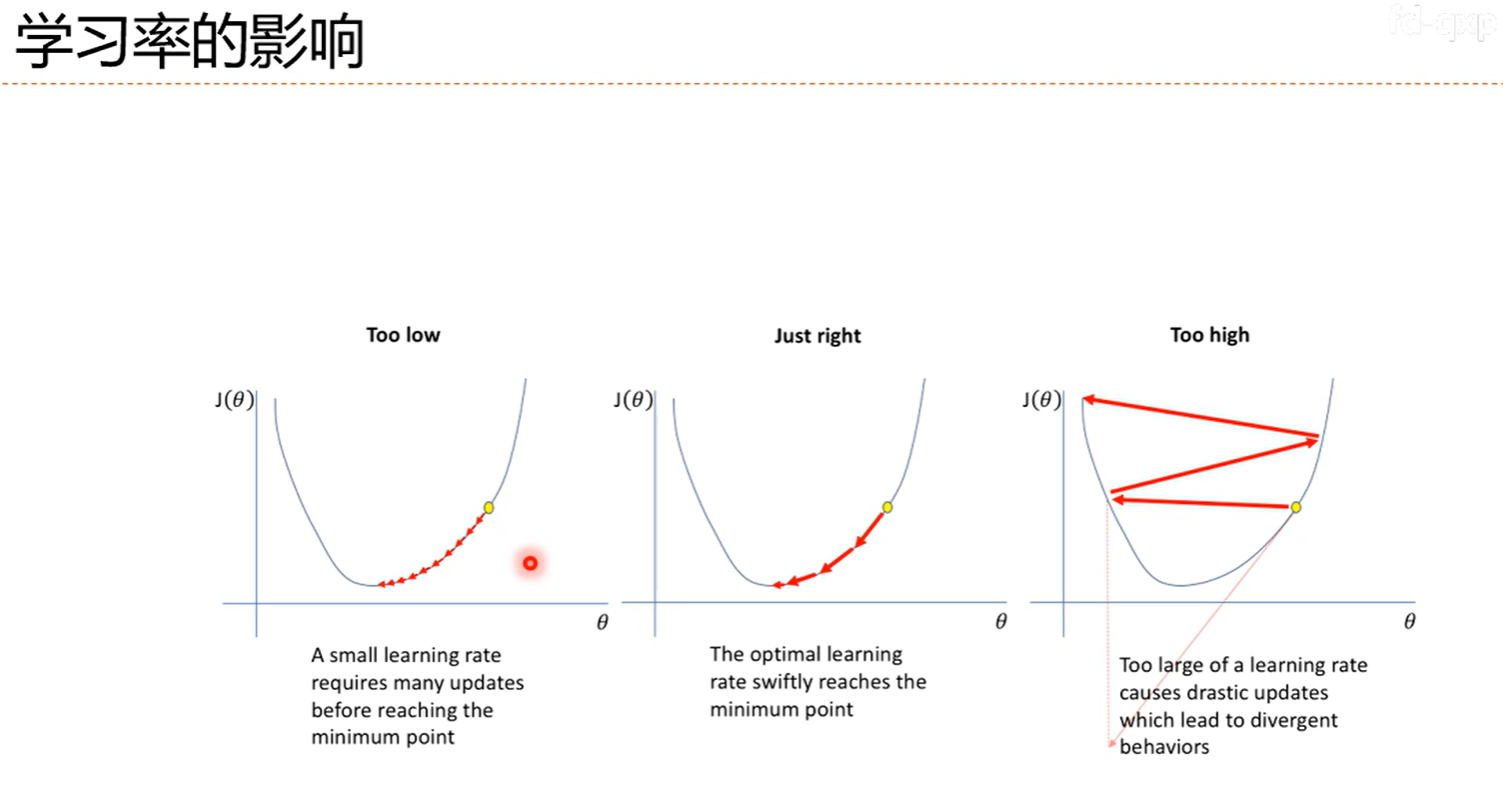
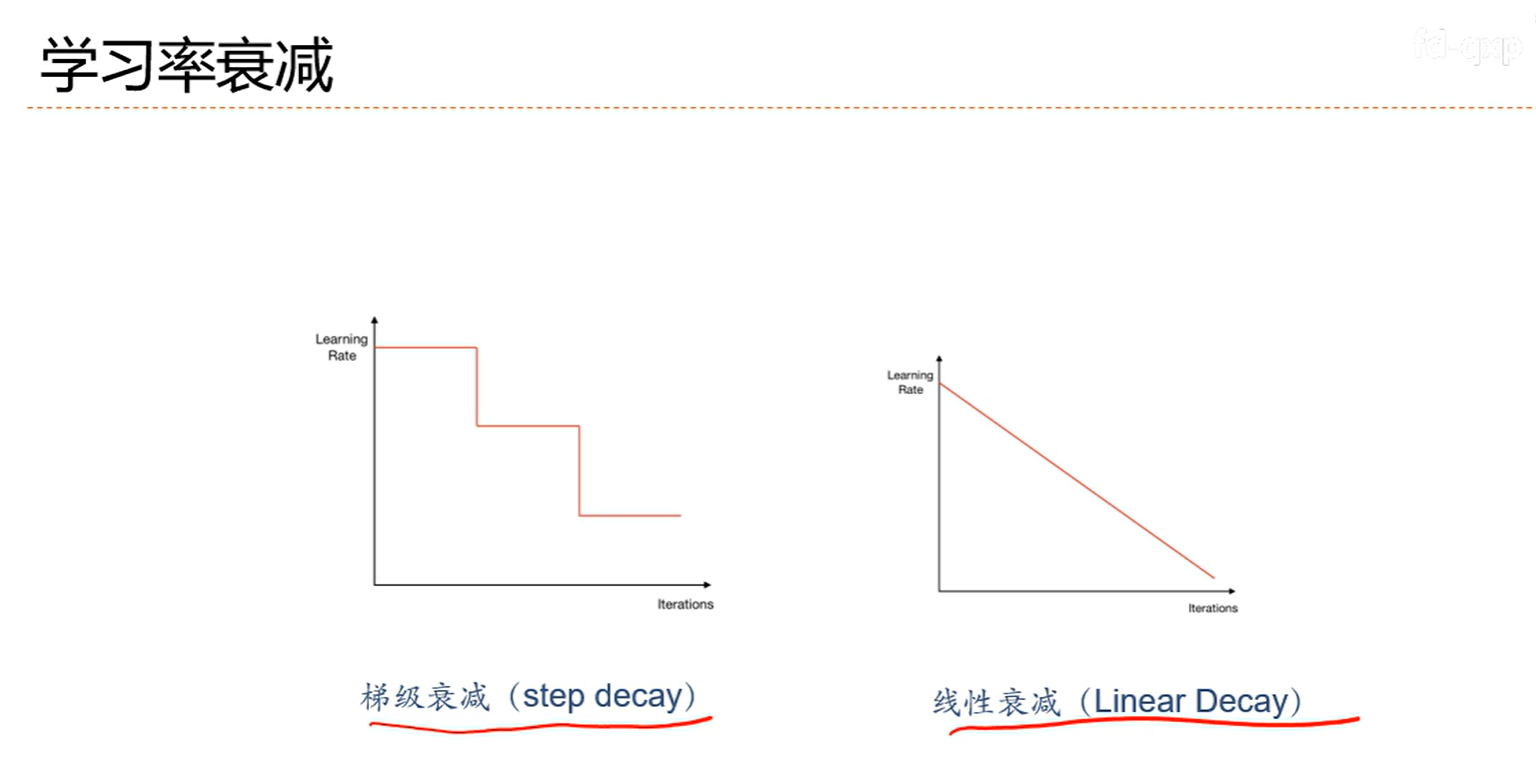

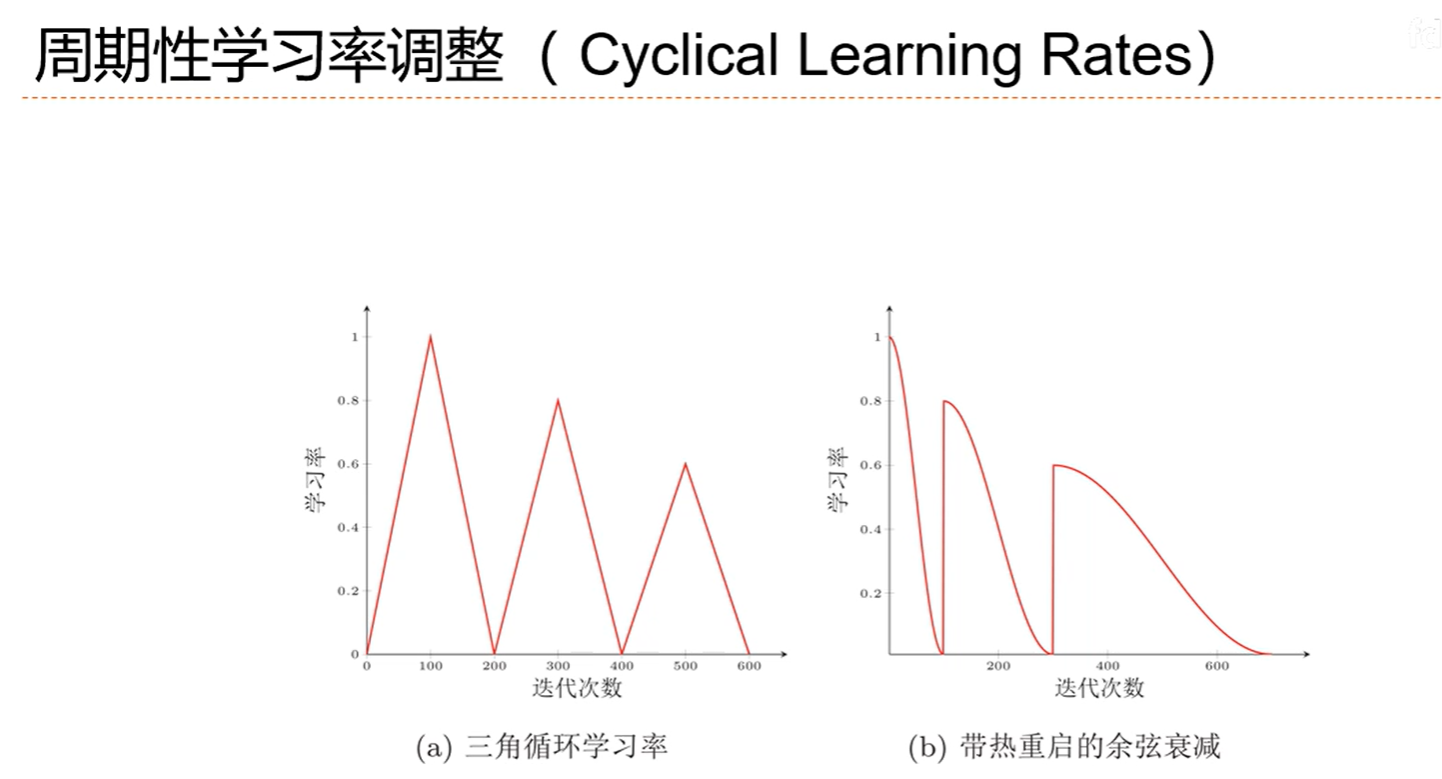
总体趋势还是减少的。时不时变大是为了找到更好的局部最优
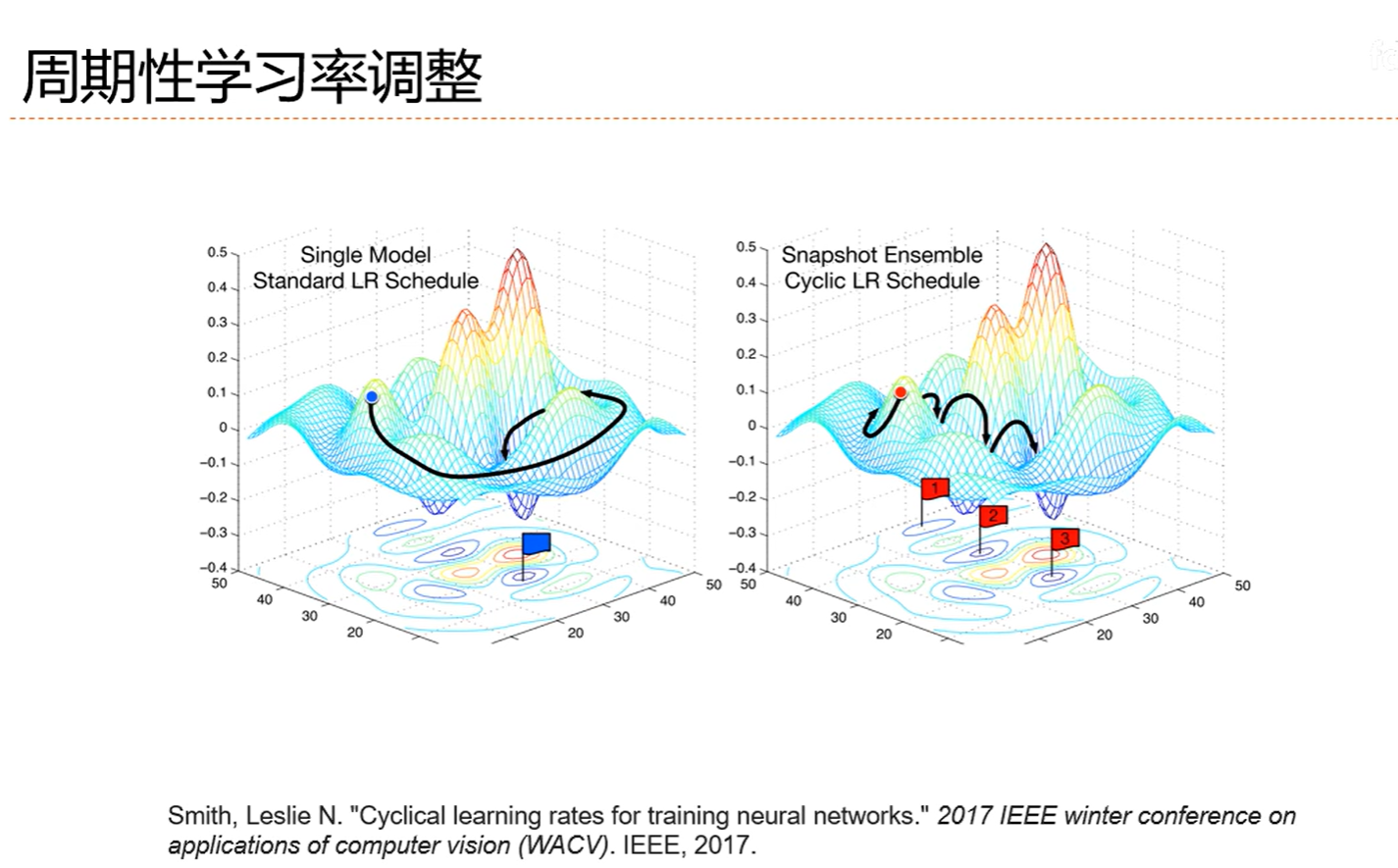
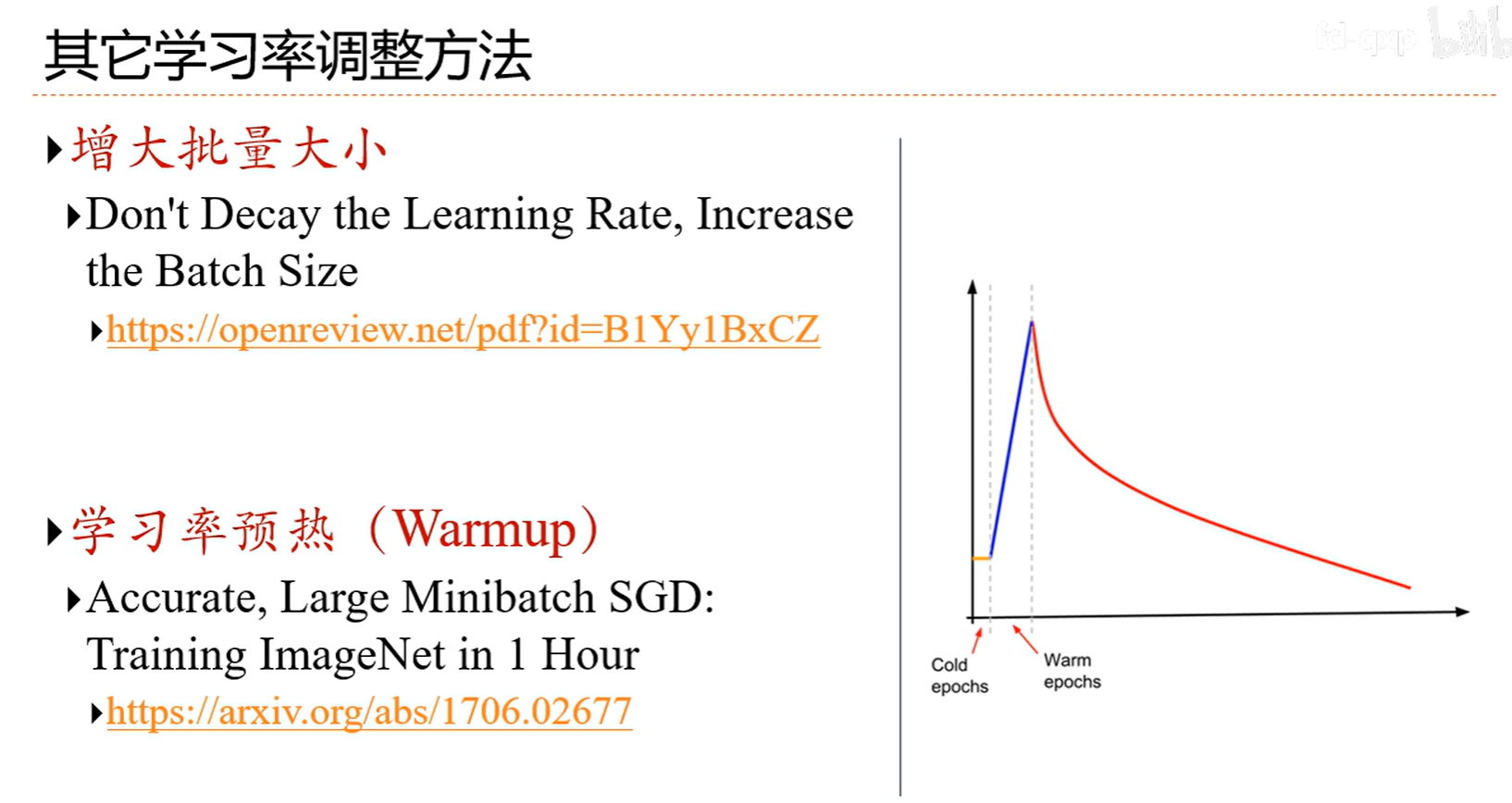
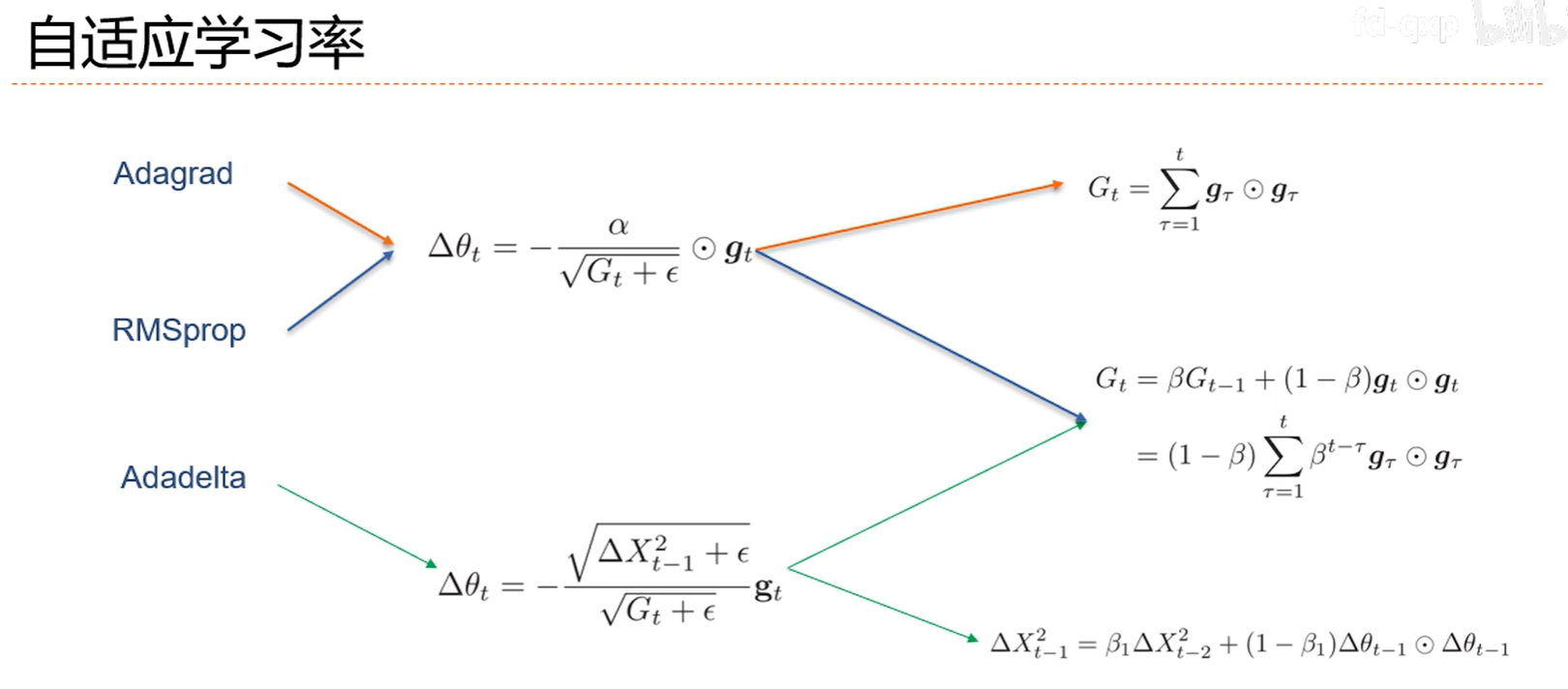
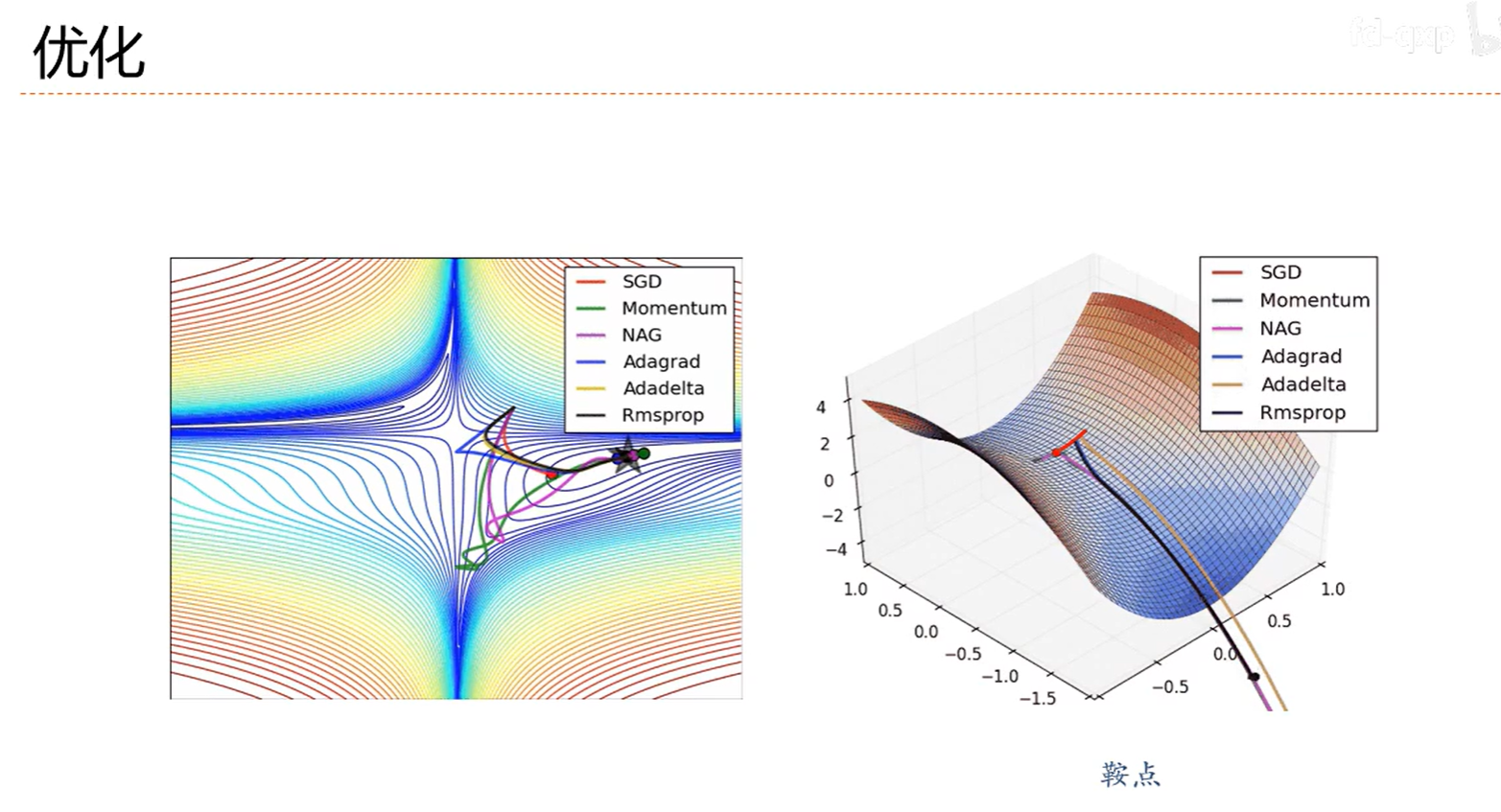
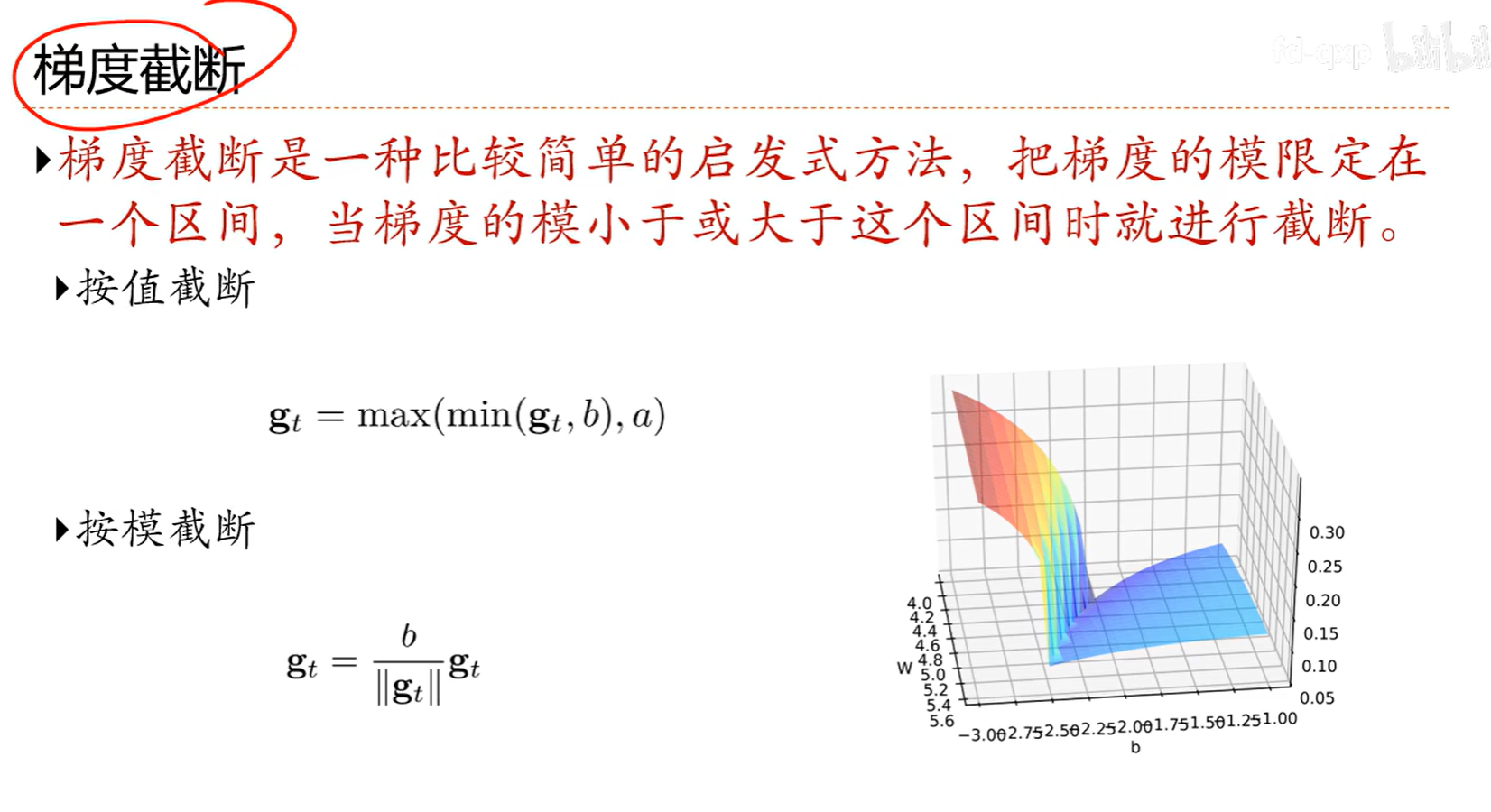
7.4 梯度方向优化
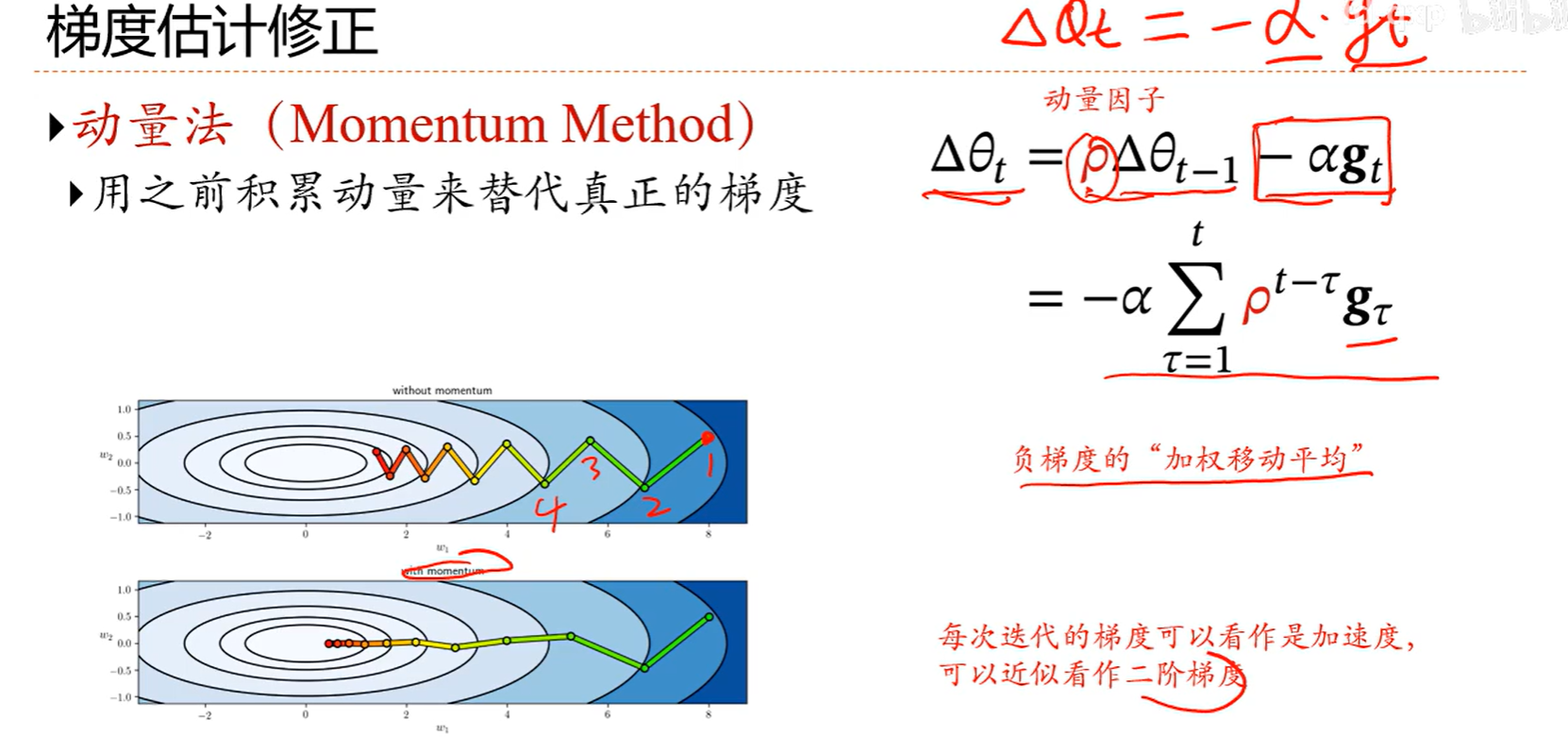
效果比随机梯度要好
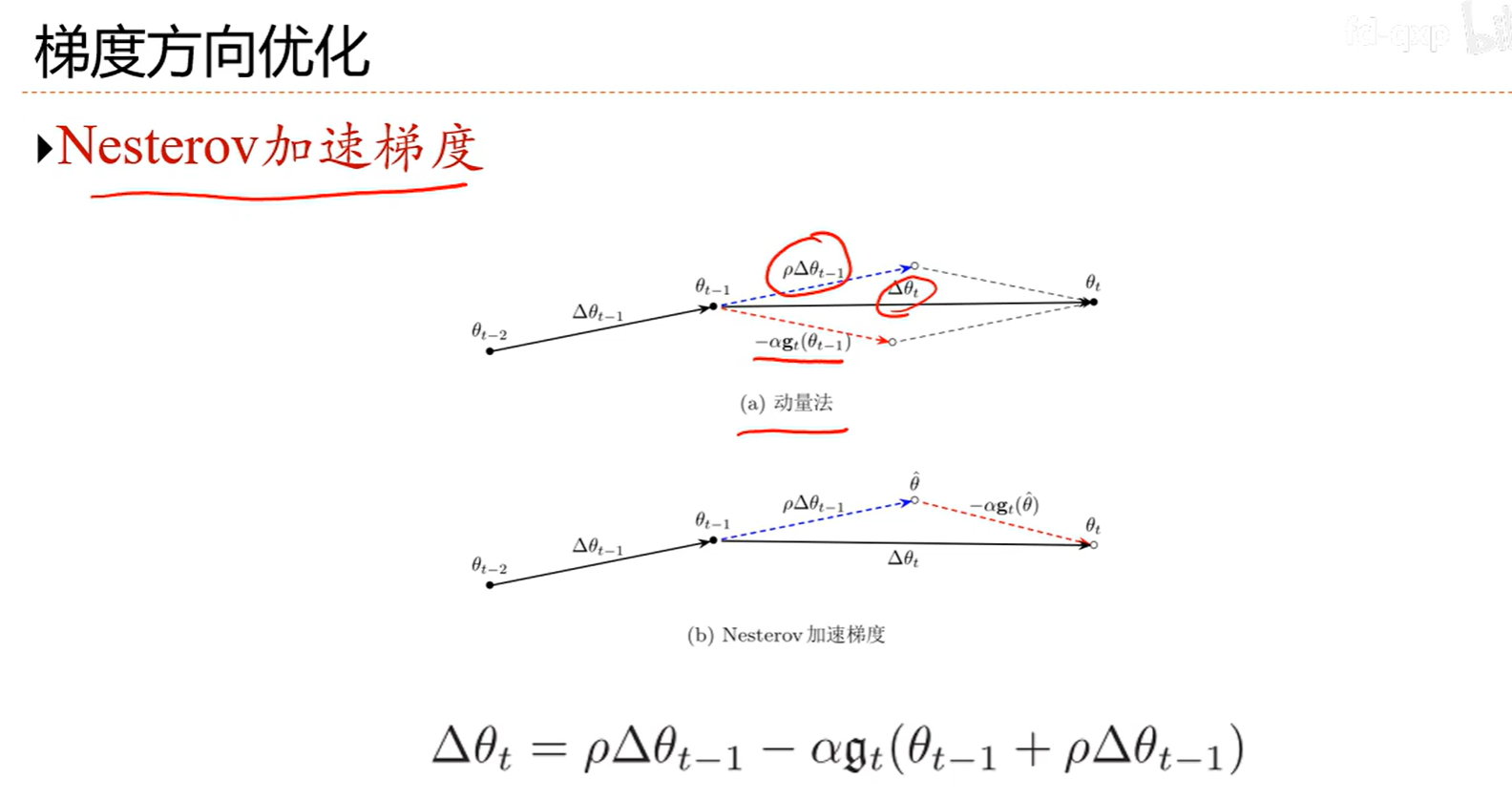


7.5 参数初始化


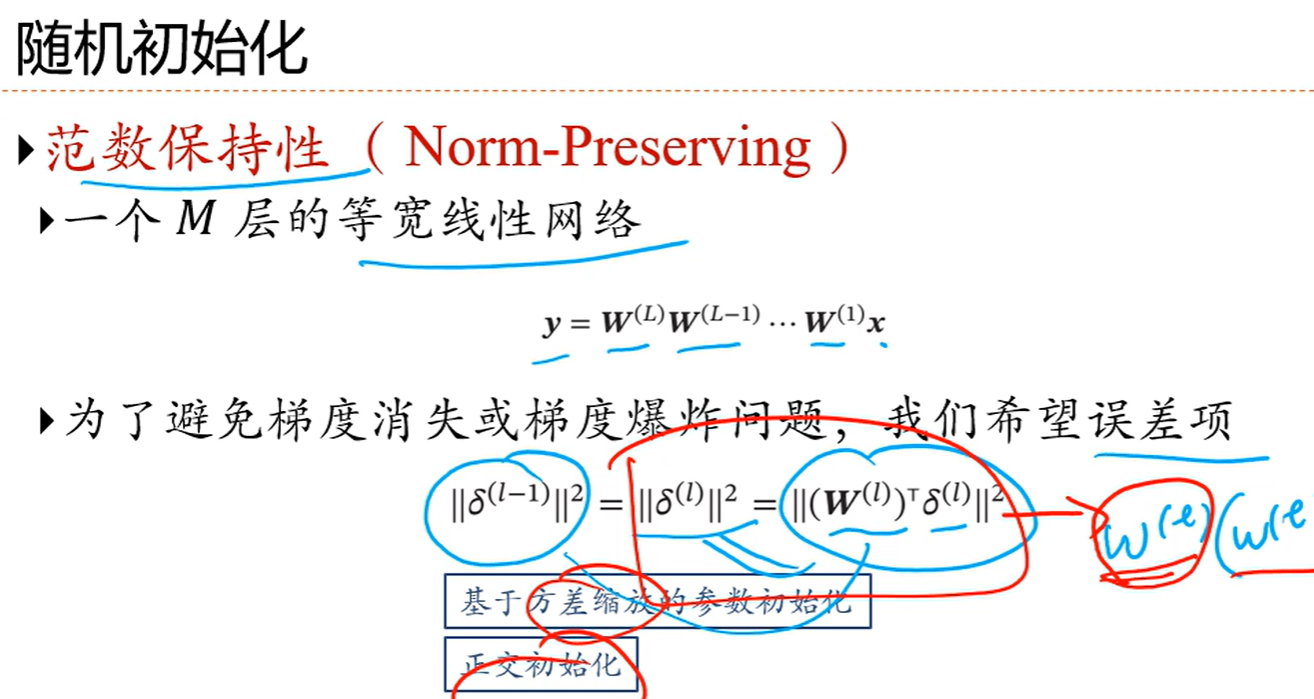


上图通常用在循环网络中
7.6 数据预处理
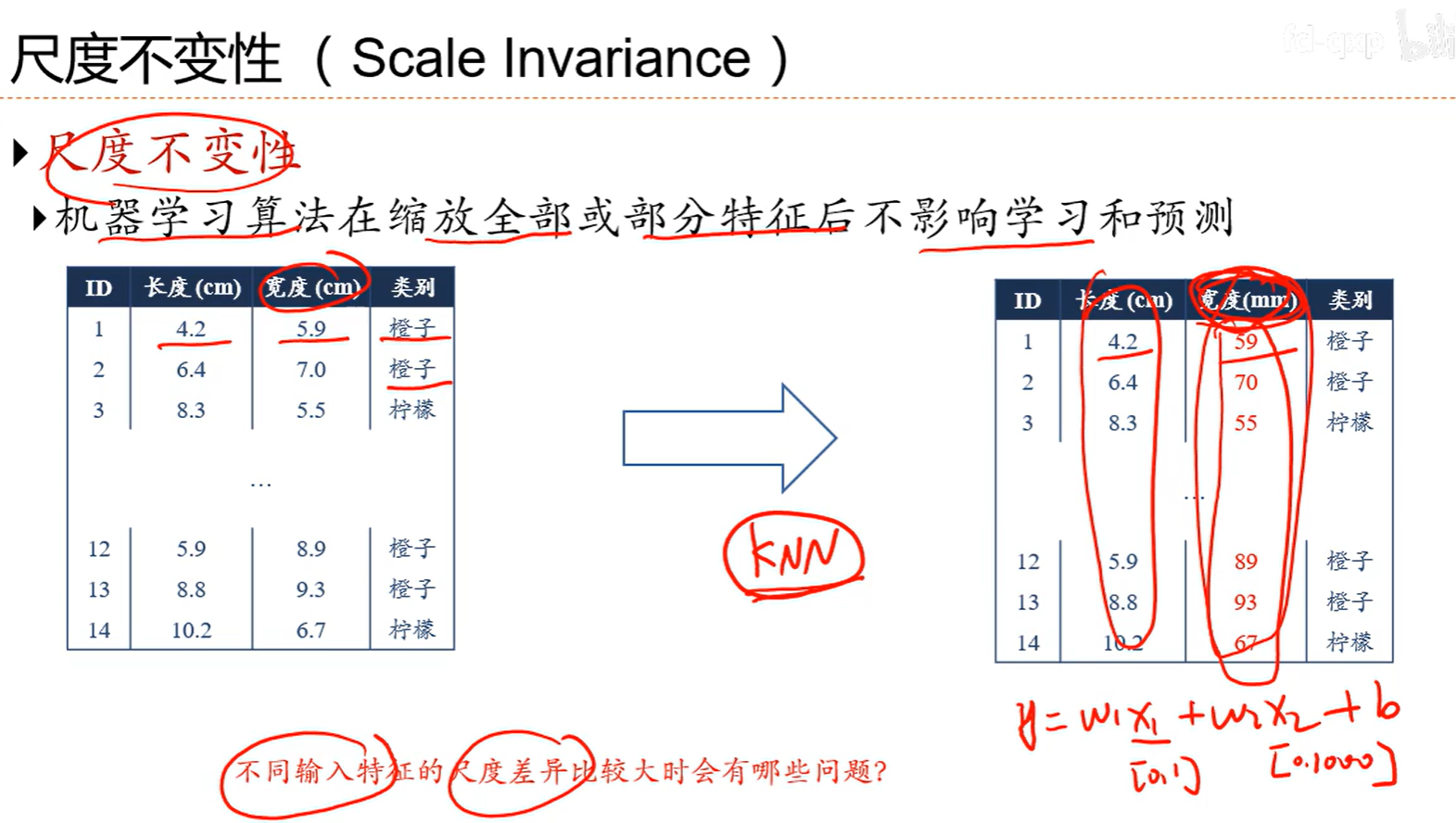
问题就是会对参数初始化产生一定的影响,也会对优化产生一定的影响
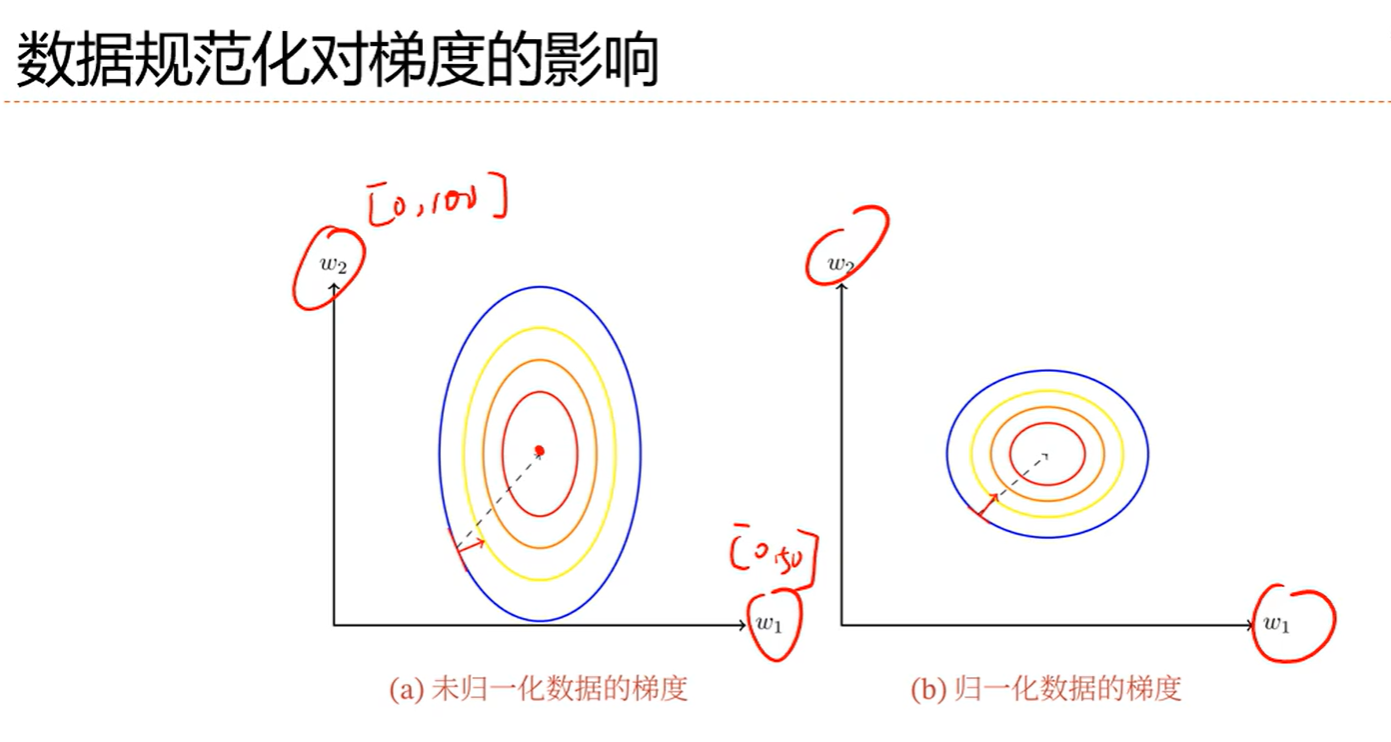

标准差为0的数据没啥意义,直接就扔了
7.7 逐层规范化




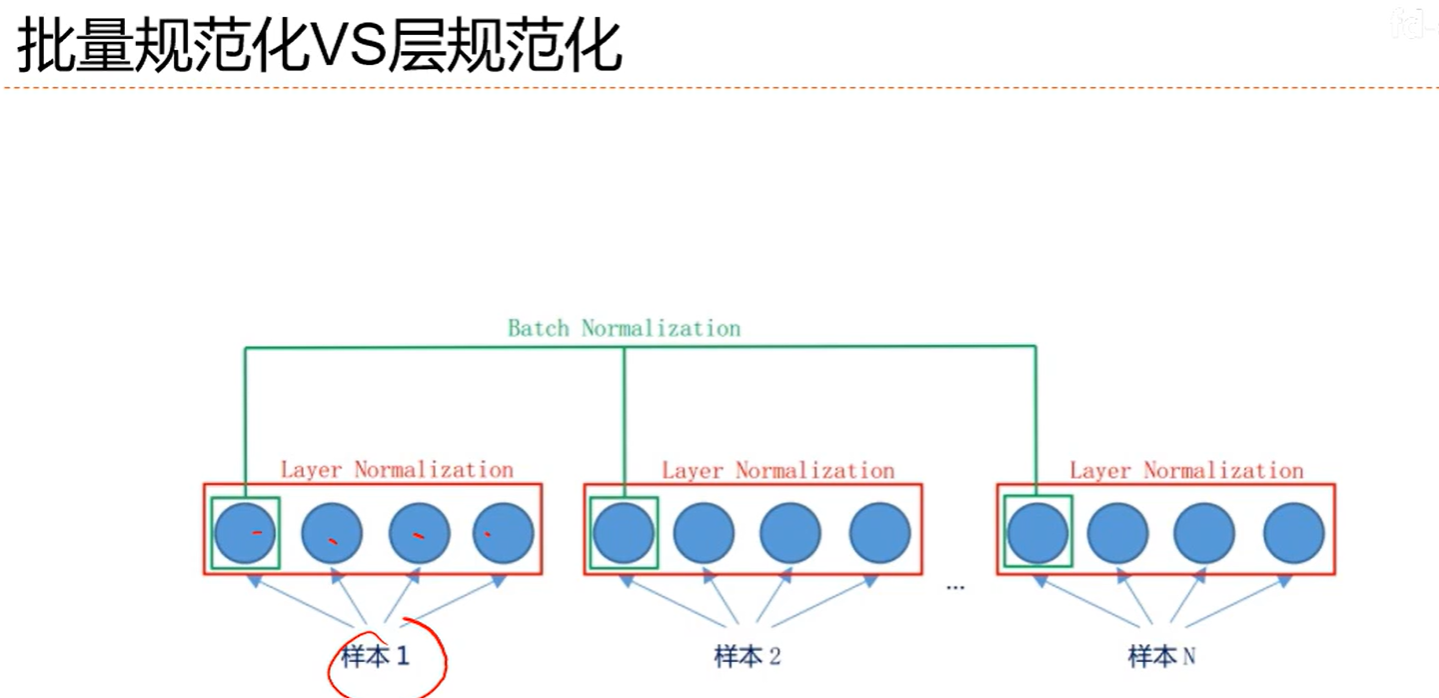
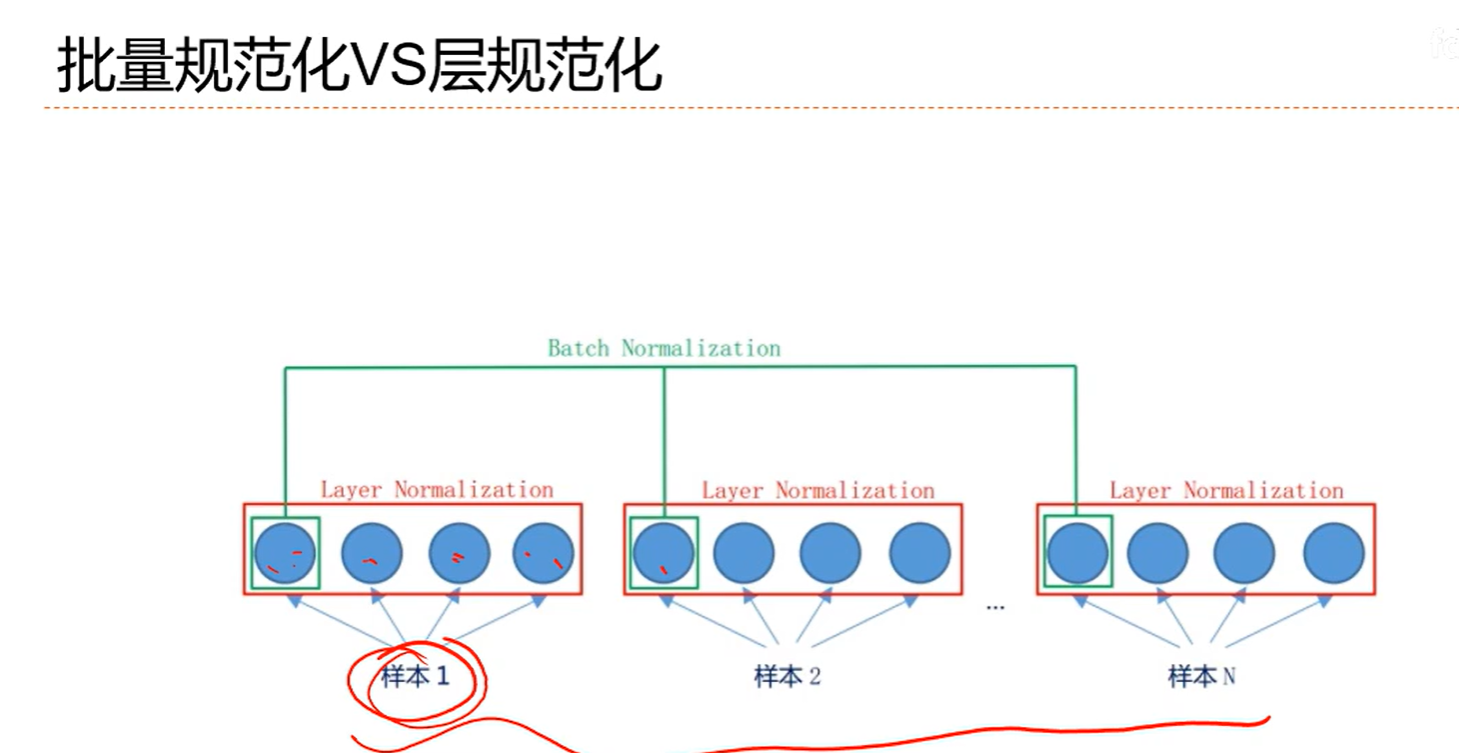
7.8 超参数优化


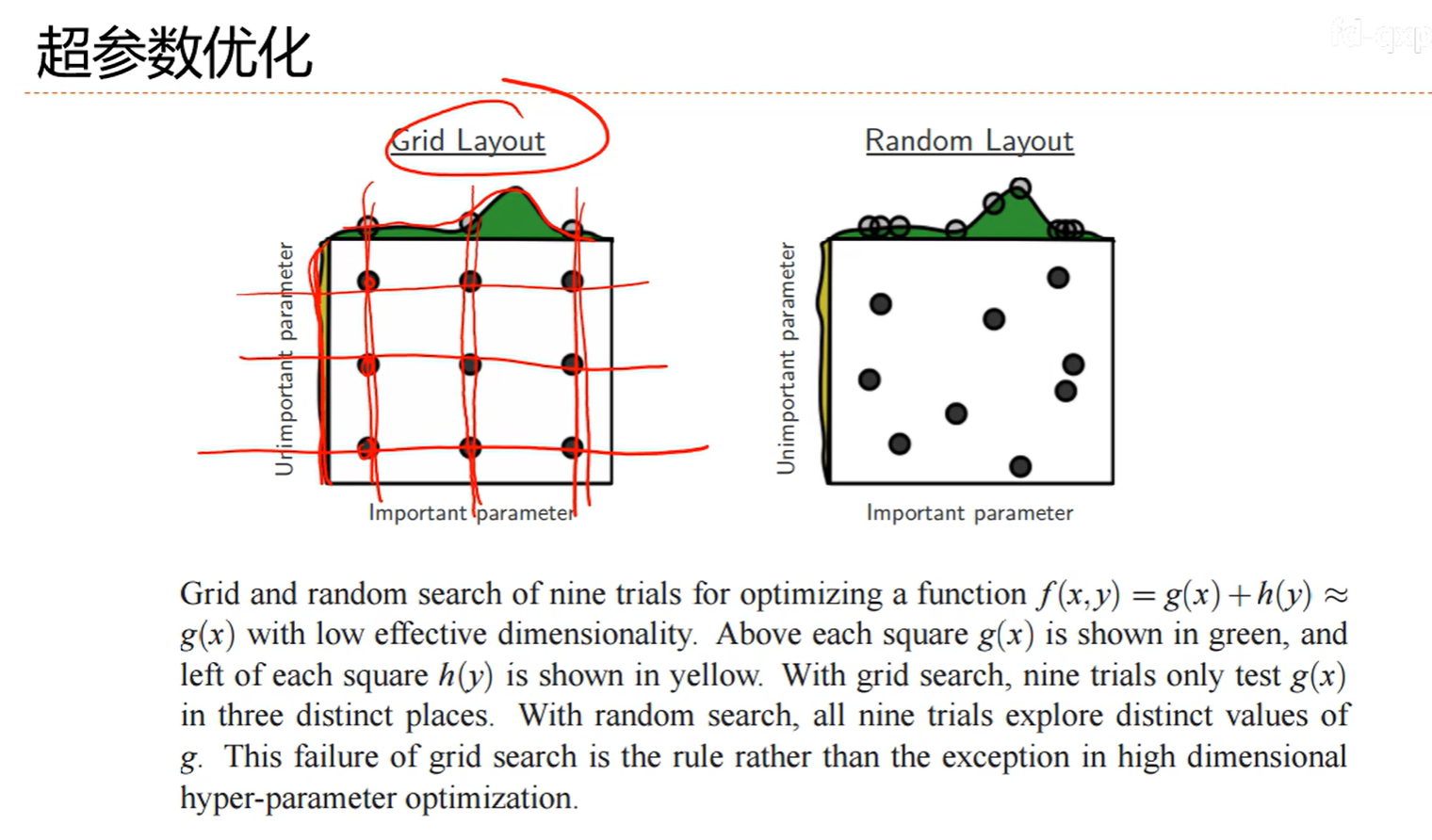
7.9 正则化
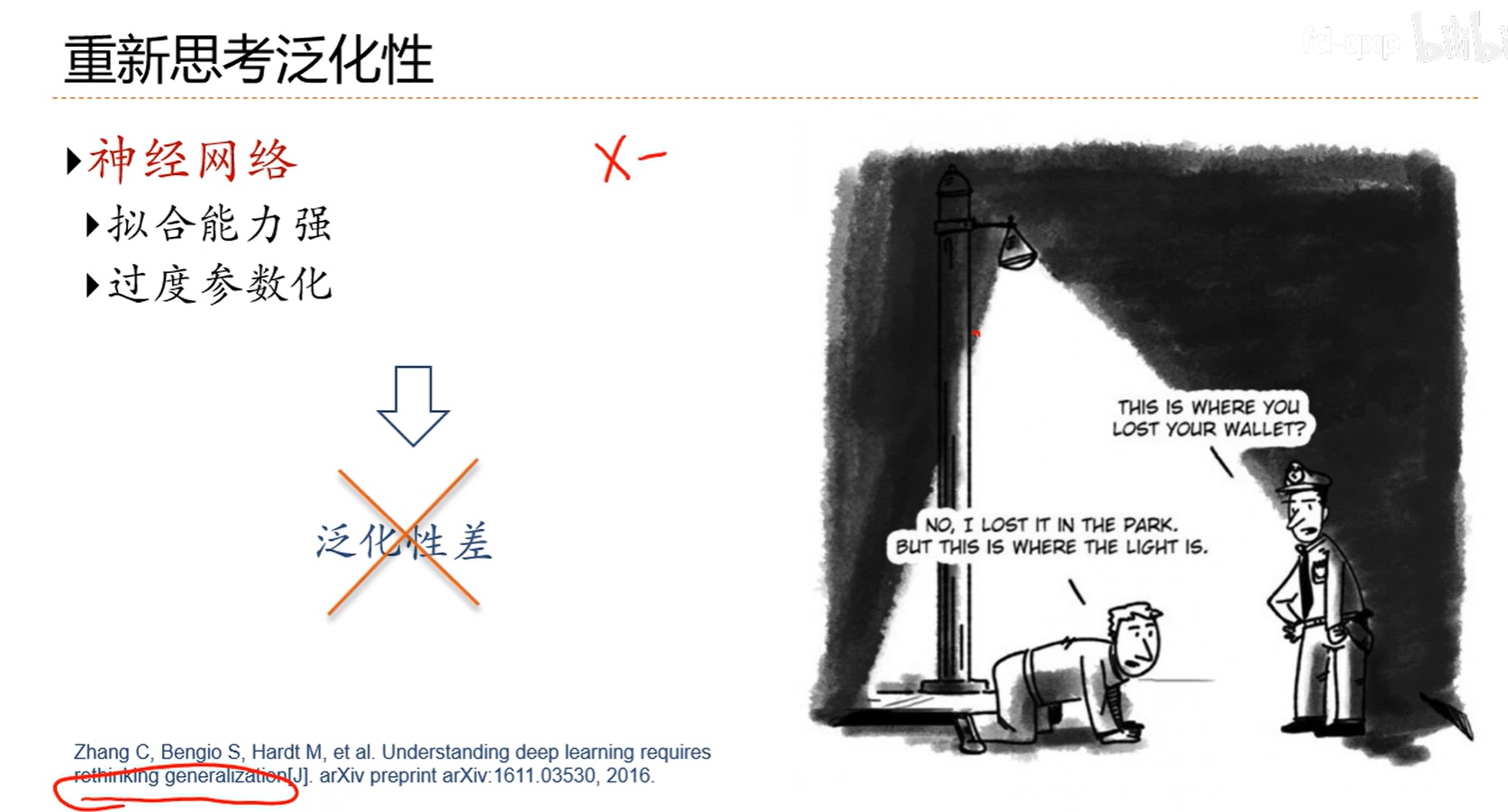
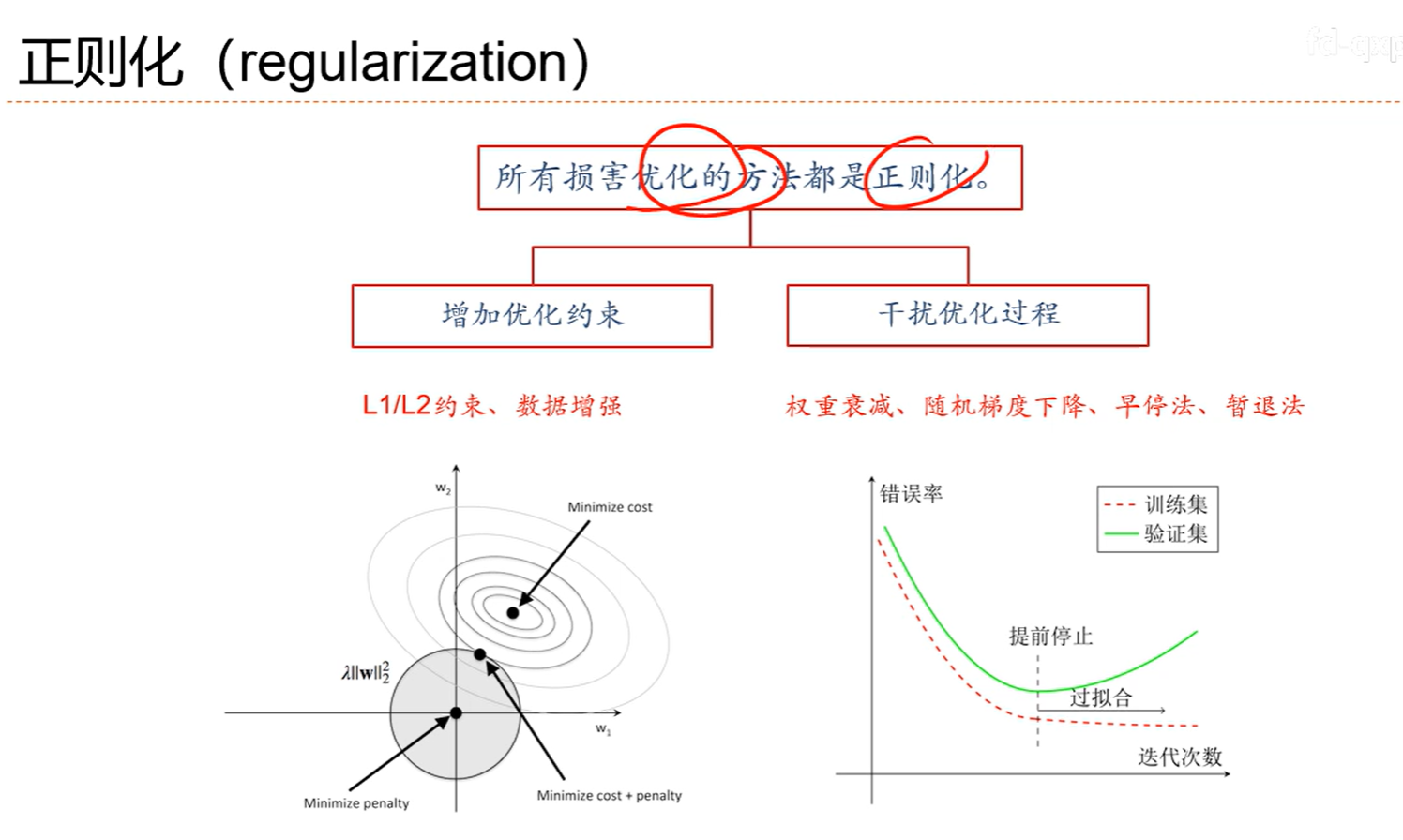

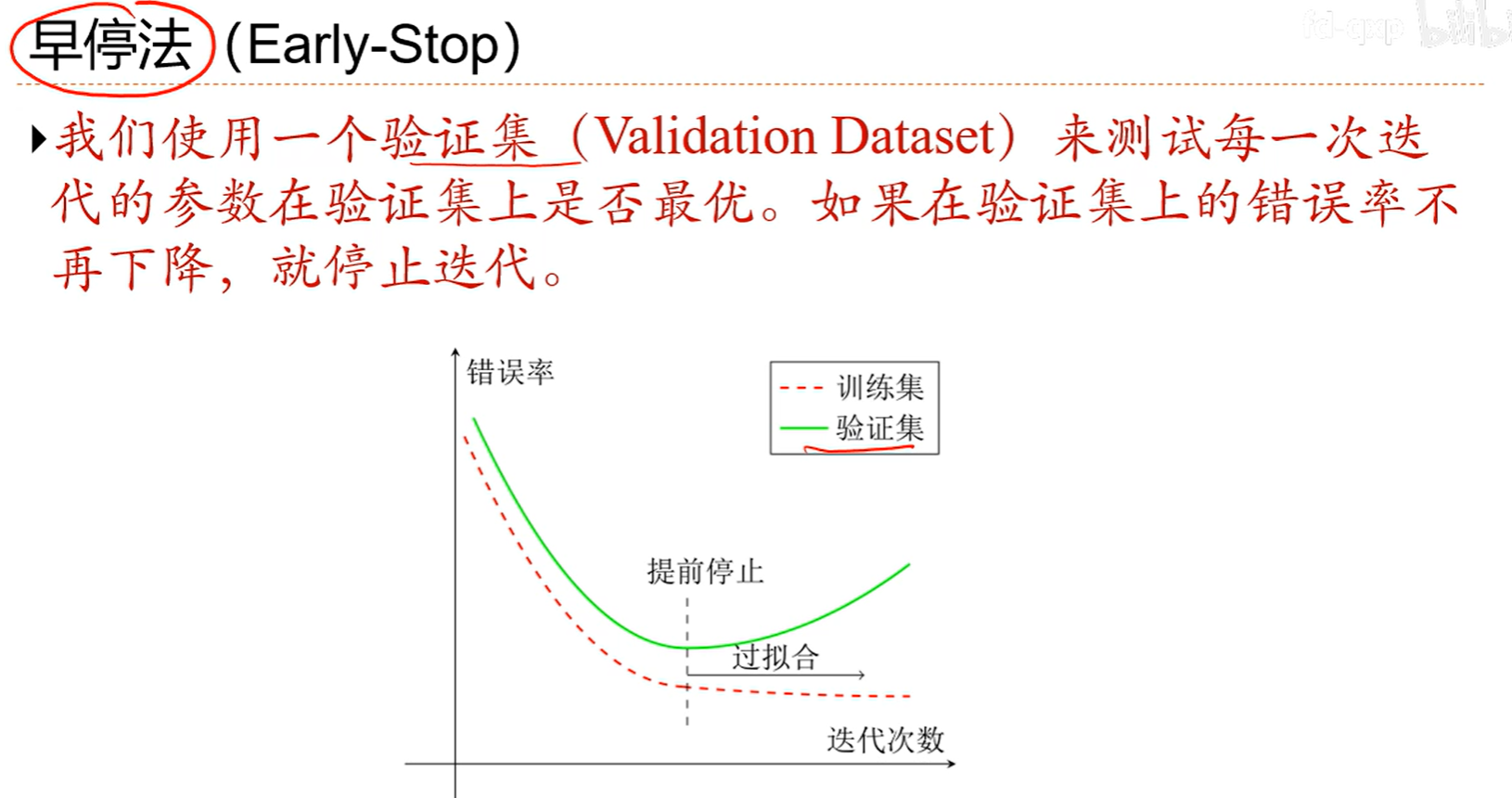

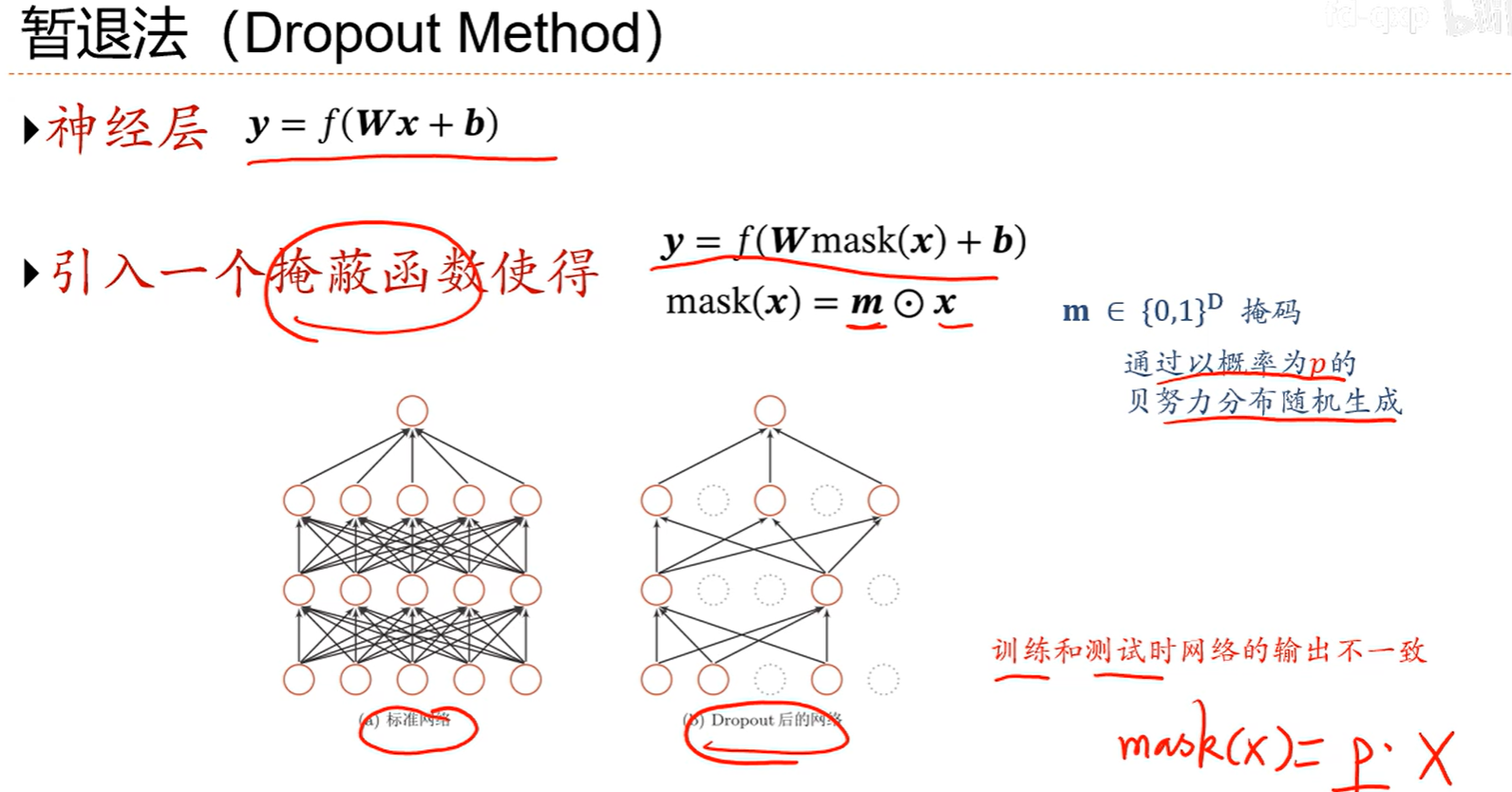
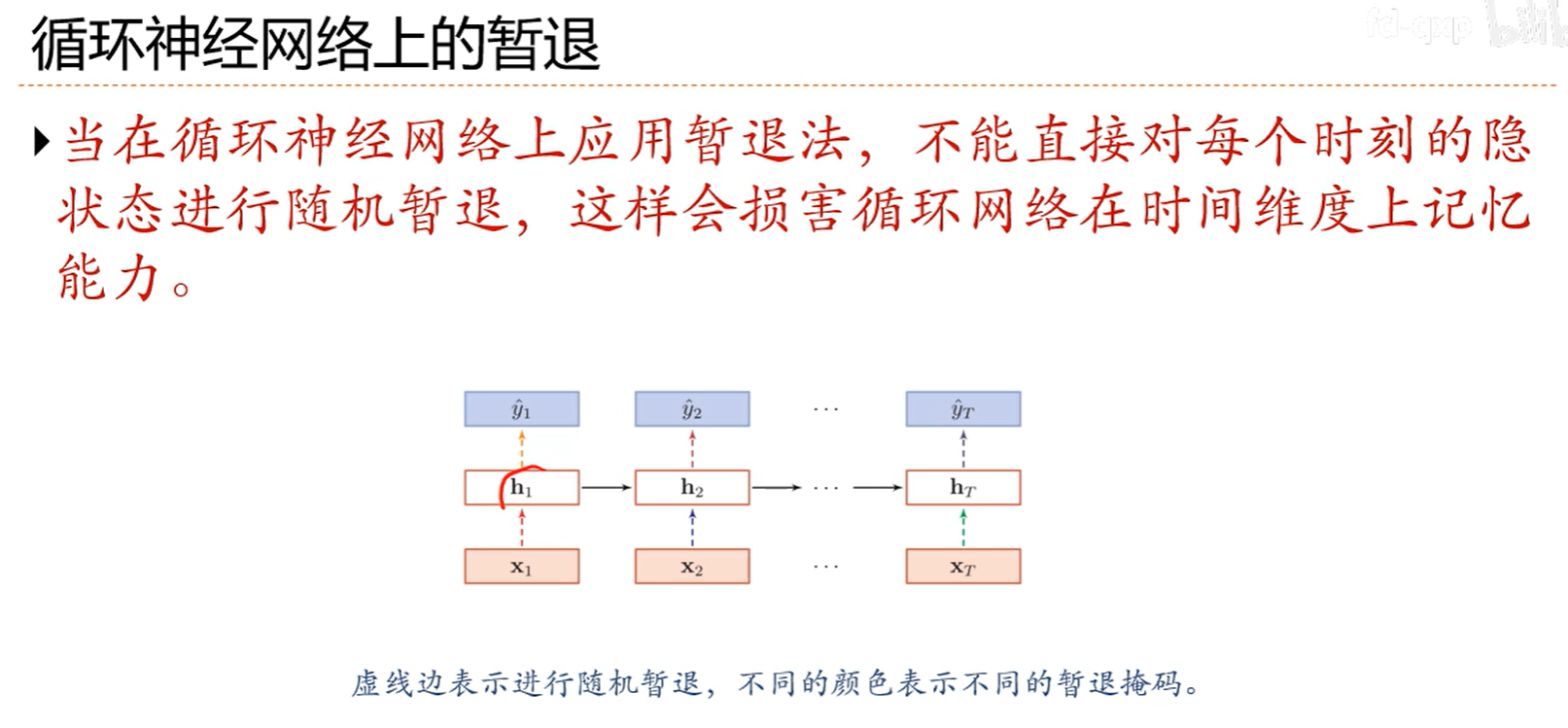
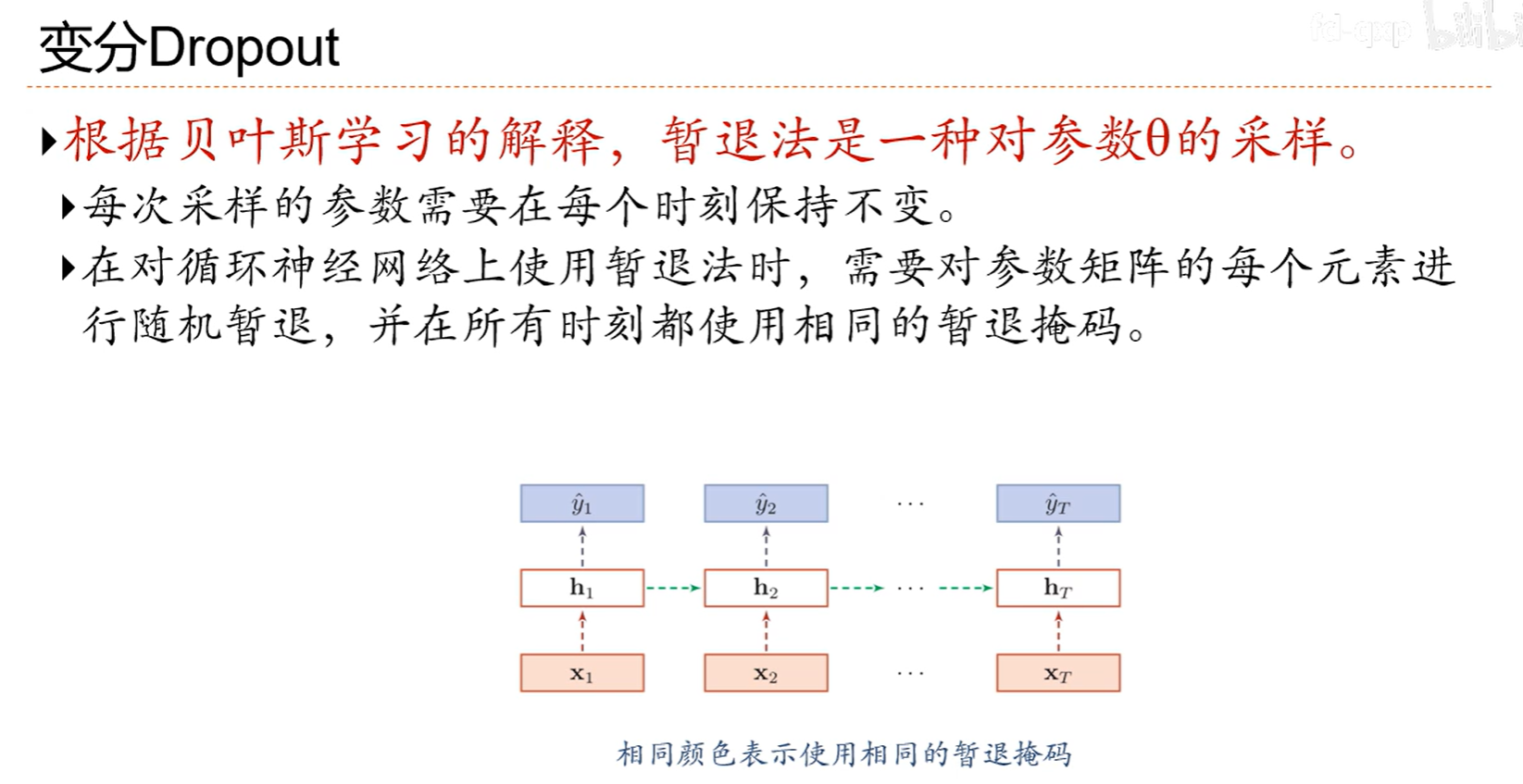
7.10 暂退法
可以提高网络的泛化能力

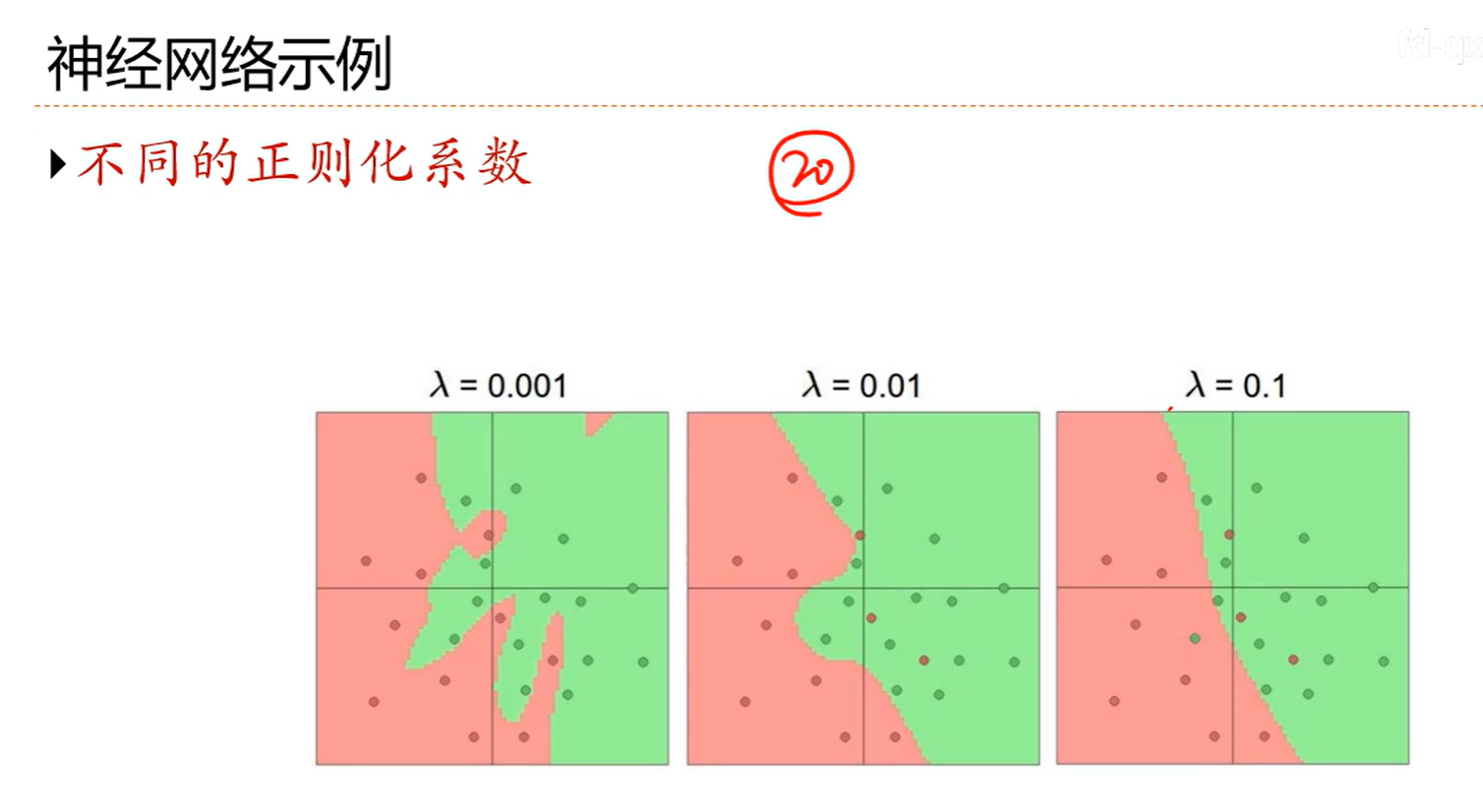
7.11 l1和l2正则化



7.12 数据增强
可以增强模型泛化能力



本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Darlingの妙妙屋!
 微信
微信 支付宝
支付宝
相关推荐

2025-03-24
深度学习与神经网络 | 邱锡鹏 | 第二章学习笔记
二、机器学习概述2.1 关于概率概率&随机变量&概率分布离散随机变量:伯努利分布:二项分布:连续随机变量:概率密度函数累计分布函数联合概率:都发生指定的情况的概率,就是相乘; 条件概率:对于离散随机向量(X,Y),已知X=x的条件下,随机变量Y=y的条件概率为 2.2 机器学习如何构建映射函数 => 大量数据中寻找规律; 机器学习(Machine Learning,ML)是指从有限的观测数据中学习(或“猜测”)出具有一般性的规律,并利用这些规律对未知数据进行预测的方法. 2.3 机器学习类型 回归问题:房价预测、股票预测等; 分类问题:手写数字识别,垃圾邮件监测、人脸检测; 聚类问题:无监督学习,比如找出相似图形; 强化学习:与环境交互来学习,比如AlphaGo; 多种模型:监督学习+无监督学习等等,自动驾驶; 典型的监督学习:回归、分类;典型的无监督学习:聚类、降维、密度估计; 2.4...

2025-06-21
深度学习与神经网络 | 邱锡鹏 | 第六章学习笔记 循环神经网络
6.循环神经网络6.1 给神经网络增加记忆能力 6.2 循环神经网络 6.3 应用到机器学习 s是单个词的意思,b是一个词的开始,e是一个词的结束 没有结果产生的部分就是编码部分,有结果产生的部分就是解码部分 这是之前说的自回归模型 6.4 参数学习 会让第t个时刻的时候收不到关于第k个时刻的损失对地t个时刻的影响 原因就是梯度爆炸或者梯度消失 6.5 如何解决长程依赖问题让上图的伽马=1即可,但是这个条件很强,很难达到 6.6 GRU 和 LSTM ft是遗忘门,说的是我们这次应该忘记多少信息 6.7 深层循环神经网络就是多叠了几层 6.8 应用 6.9 扩展到图结构

2025-04-03
深度学习与神经网络 | 邱锡鹏 | 第三章学习笔记
三、线性模型softmax是用的改进版一对其余,而剩下的都是二分类的线性模型,即g(f(x))形式,不一样的是他们使用了不同的损失函数,这会导致他们学出来的模型不一样,所以取的名字也不一样 3.1 分类问题示例图像识别,垃圾邮件过滤,文档归类,情感分类这些都是分类问题 3.2 线性分类模型fx是判别函数,g(f(x))是决策函数 0和1表示正类和负类 一条线把两个分类隔开 有了模型下一个就是学习准则就是损失函数,01损失函数不可求导,无法转化为最优化问题所以要重新选择一个更好的损失函数 多分类不可以用一个函数表示,那就表示要用多个函数表示 虽然是改进的一对其余,但是仍然是不可导的,那说明我们还是得去找一个更好的损失函数 3.3...

2025-06-21
深度学习与神经网络 | 邱锡鹏 | 第五章学习笔记 卷积神经网络
五、卷积神经网络 我们希望有一个新的网络可以提取局部不变性 5.1 卷积 前两个输入都不卷,从第三个开始卷,因为滤波器的长度是3 每次选定三个数卷,比如前三个,1,1,2 2* (-1) + 1*0+1*1= -1 然后根据公式就是如上计算,就是滤波器的第三个对应当前选定的三个值的第一个,第二个对第二个,第一个对第三个,其实就是倒着来的,后面的也都是如此 然后可以看到,输入有7个,输出有5个,滤波器大小是3,那么关系就是7-3+1=5 也就是n-k+1=5 零填充很常用,因为这个可以让输入和输出长度相同 比如图中输入是7,滤波器是3,输出本来应该是5,现在零填空P=1,那就是补了两个零,表面上输入好像成9了,这么一算,输出就是7,但实际上输入还是原来的7,因为那两个0是补进去的 其实P=(k-1)/2,也就是输入会补k-1个0 5-3+1=3,依旧满足上面那个规则 5.2...

2025-04-07
深度学习与神经网络 | 邱锡鹏 | 第四章学习笔记 神经网络
四、神经网络4.1 神经元 w表示每一维(其他神经元)的权重,b可以用来调控阈值,z 经过激活函数得到最后的值a来判断神经元是否兴奋,1就兴奋,0就不兴奋 这就相当于一个简单的线性模型 第二点要求函数和导函数尽可能简单是因为,我们的网络可以设计的比较复杂,所以函数就设计的比较简单,有利于提高网络计算效率 最后一点,函数并不一定是单调递增的,可能局部会递减,但是我们希望的是a可以反映出z的变化 现在复合用的挺多的 非零中心化去w求导,前面是标量,后面seigema...

2025-03-17
深度学习与神经网络 | 邱锡鹏 | 第一章学习笔记
深度学习与神经网络 | 邱锡鹏 | 第一章学习笔记参考自下面这篇博客,笔者在此基础上写了写自己的理解,仅自己用来复习使用 【学习笔记】《深度学习与神经网络》——邱锡鹏_神经网络与深度学习 邱锡鹏-CSDN博客 一、绪论人工智能的一个子领域神经网络:一种以(人工))神经元为基本单元的模型深度学习:一类机器学习问题,主要解决贡献度分配问题 知识结构:路线图:顶会: 1.1 人工智能诞生:人工智能这个学科的诞生有着明确的标志性事件,就是1956年的达特茅斯(Dartmouth)会议。在这次会议上,“人工智能” 被提出并作为木研究领域的名称。 人工智能=计算机控制+智能行为; 人工智能就是要让机器的行为看起来就像是人所表现出的智能行为一样。 ——John McCarthy ( 1927-2011) 因为要使得计算机能通过图灵测试,计算机必须具备理解语言、学习、记忆、推理、决策等能力 =>研究领域: 机器感知(计算机视觉、语音信息处理、模式识别) 学习(机器学习、强化学习) 语言(自然语言处理) 记忆(知识表示) 决策(规划、数据挖掘) 发展时间轴: 1.2...
评论




