GO学习笔记 | 第九章节 JWT、Redis 入门与 K8s 部署实战| K8s 部署 web服务、 MySQL、Redis 与 Ingress
GO学习笔记 | 第九章节 JWT、Redis 入门与 K8s 部署实战| K8s 部署 web服务、MySQL、Redis 与 Ingress
代码仓库地址:Darling-123456/go_learning: go学习过程记录
核心内容:kubectl 日志调试、K8s部署web服务、K8s 部署 MySQL、K8s 部署 Redis、Ingress 七层路由、环境变量配置、K8s 面试要点
前置知识:K8s Deployment/Service 基本概念、Docker 镜像
一、kubectl 常用调试命令
1.1 查看 Pod 日志
1 | # 查看指定 Pod 的日志 |
-f相当于tail -f——应用有新日志就实时显示,排查问题非常实用。
1.2 查看 Pod 详细信息
1 | # 查看 Pod 的状态、事件、配置等 |
当 Pod 起不来时,describe 可以看到具体原因(镜像拉不下来?端口冲突?资源不够?)。
1.3 常用命令速查
| 命令 | 作用 |
|---|---|
kubectl get pods |
列出所有 Pod |
kubectl get services |
列出所有 Service |
kubectl get deployments |
列出所有 Deployment |
kubectl logs <pod> |
查看 Pod 日志 |
kubectl logs -f <pod> |
实时跟踪日志 |
kubectl describe pod <pod> |
查看 Pod 详细状态 |
kubectl apply -f xxx.yaml |
应用配置 |
kubectl delete -f xxx.yaml |
删除配置 |
二、Kubernetes 部署web
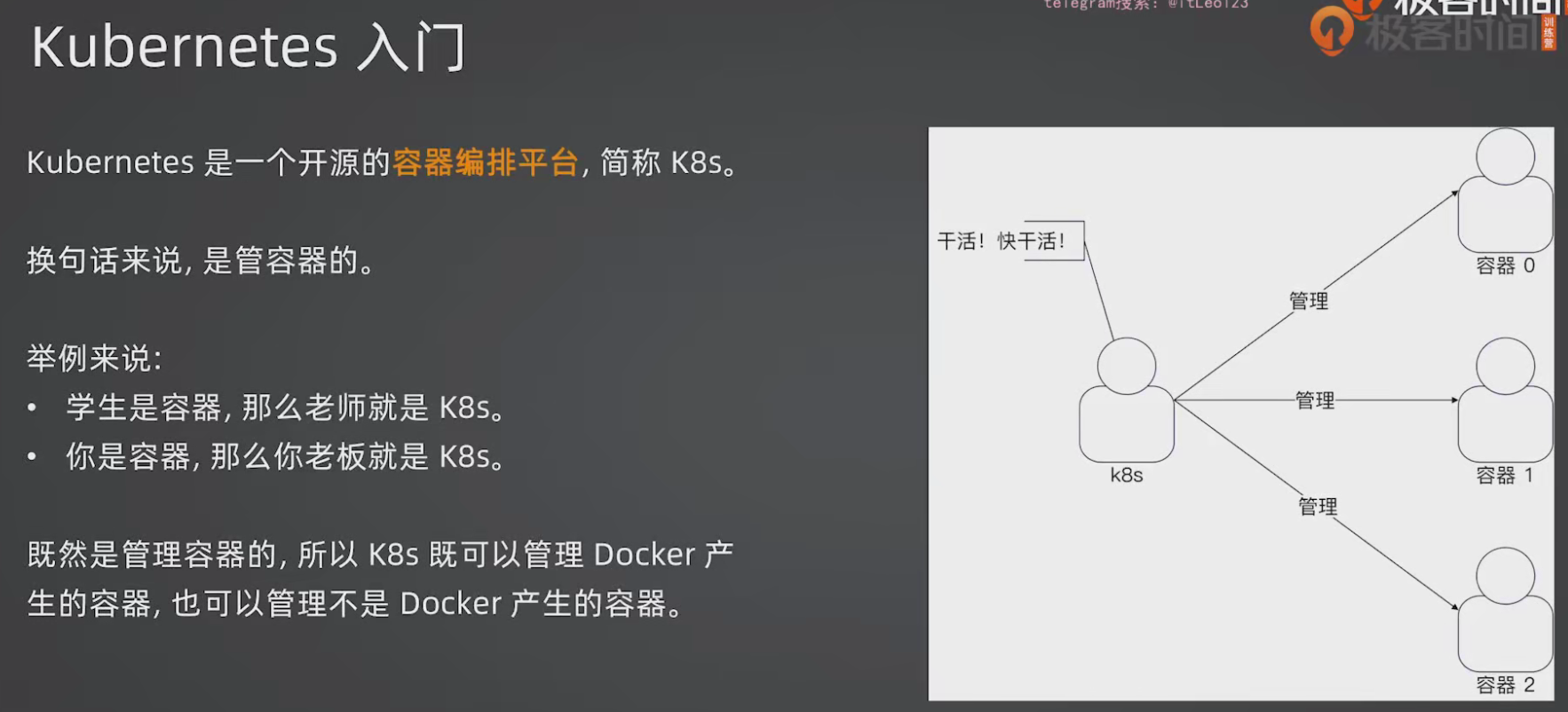
2.1 K8s 是什么?
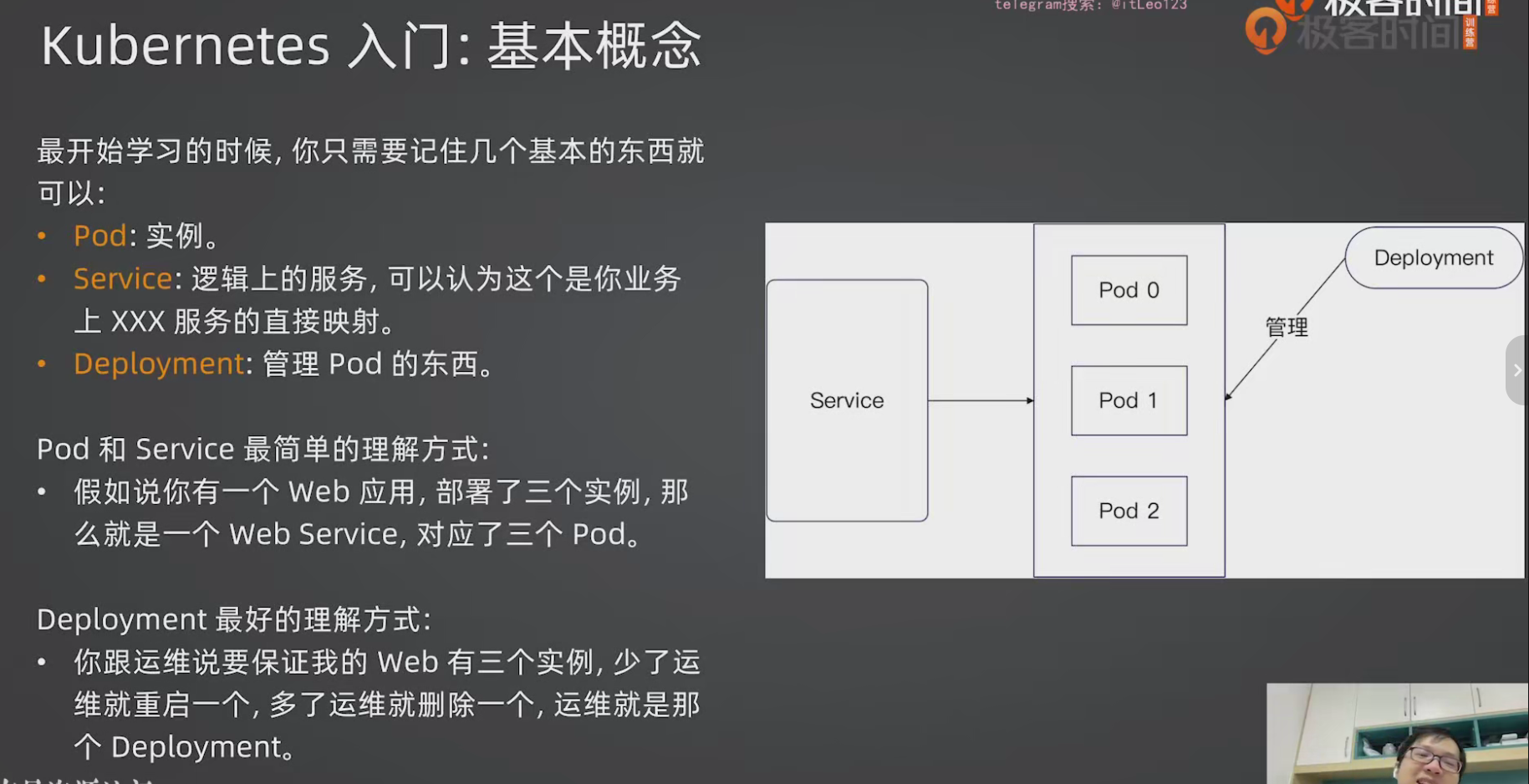
核心三件套:
| 概念 | 一句话 |
|---|---|
| Pod | 最小的部署单元,一个 Pod 跑一个实例 |
| Service | 逻辑上的服务入口,对 Pod 做负载均衡 |
| Deployment | 管理 Pod 的控制器,保证 Pod 数量正确 |
一个pod里面可以跑很多个容器。deployment管理:如果它管3个pod,其中有一个崩了,那它就帮你启动一个pod,如果多了一个pod变成4个了,那就帮你删掉一个
外卖餐厅类比(最通俗易懂)
- Pod → 【后厨的工位 / 厨师团队】
- 一个工位可以有 1 个主厨(主业务容器),也可以配几个帮厨(Sidecar 辅助容器,如给主厨递调料/做记录的)。主厨挂了,整个工位完蛋。
- Service → 【外卖平台的固定商家电话/门店入口】
- 不管后厨哪个厨师在掌勺,甚至厨师换了一拨人(Pod 漂移),顾客(客户端)始终只需要拨打这个固定的电话(Service 的 ClusterIP),或者点击这个店铺入口。电话会自动把订单分配给此时此刻正在上班的厨师(负载均衡)。
- Deployment → 【餐厅店长】
- 店长定下了后厨必须要有 3 个工位(Replicas=3)。如果有工位塌了(Pod 挂掉),店长立刻指挥搭建一个新工位顶上去(自动自愈)。换新菜单时,店长保证逐批更新工位,避免同时停摆(滚动更新)。
微服务/数据中心架构类比(更符合 Go 后端工程师直觉)
- Pod → 【一台物理机上的微服务实例(进程)】(对应 IP 属性)
- 它有自身的 IP 地址,如果这个进程崩溃了,机器重启后得到一个新的 IP。
- Service → 【负载均衡器(Nginx 上的 Upstream 或云厂商的 SLB)】(对应访问入口)
- 不管背后的微服务实例 IP 怎么变,客户端访问的 VIP(虚 IP)永远是固定的,SLB 会自动把请求转发给背后存活的实例。
- Deployment → 【运维自动化脚本(或 Ansible 机器人)】(对应调度者)
- 它负责启动进程、监测进程存活数、如果进程挂了就重新启动。它是整个服务生命周期的管家。
2.2 Docker 启用 K8s 支持 && 安装kubectl
学习阶段直接用 Docker Desktop 内置的 K8s,在设置里勾选 Enable Kubernetes 即可。

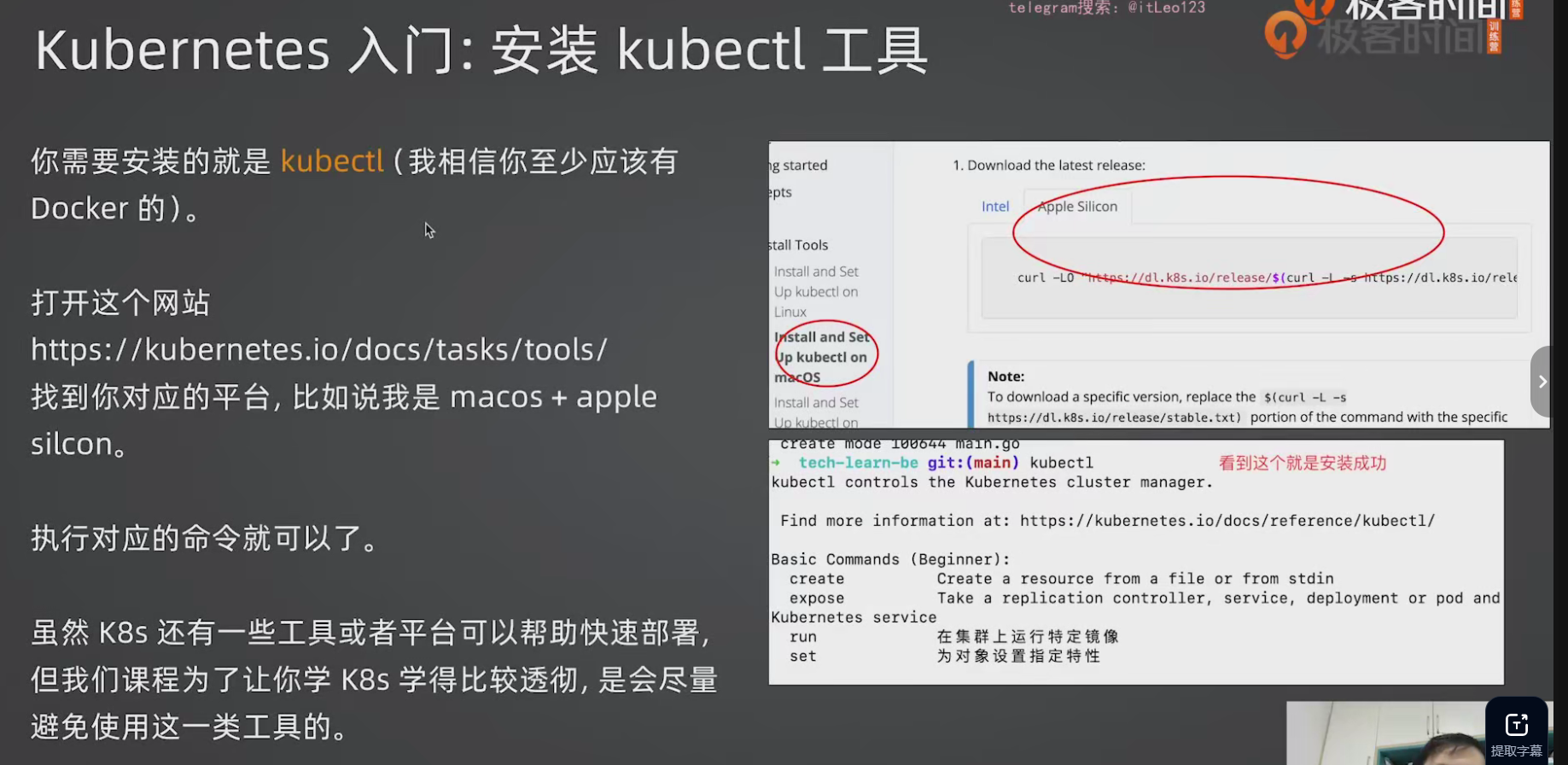
在windows下用管理员运行
1 | winget install Kubernetes.kubectl |
安装完成后,重新打开一个新的cmd,输入下面的命令
1 | kubectl version --client |
1 | #成功之后的 |
如果输出系统无法执行制定程序的话,输入这个命令
1 | where kubectl |
它会给你打印出 Windows 到底是从哪个文件夹里找的 kubectl.exe。
- 如果是类似
C:\Users\你的用户名\kubectl.exe,那绝对就是那个 2KB 的坏文件。找到它之后,去那个文件夹里,把这个kubectl.exe删掉!
然后重新输入,看看是不是输出版本号就行了
2.3 用Kubernetes部署web服务器
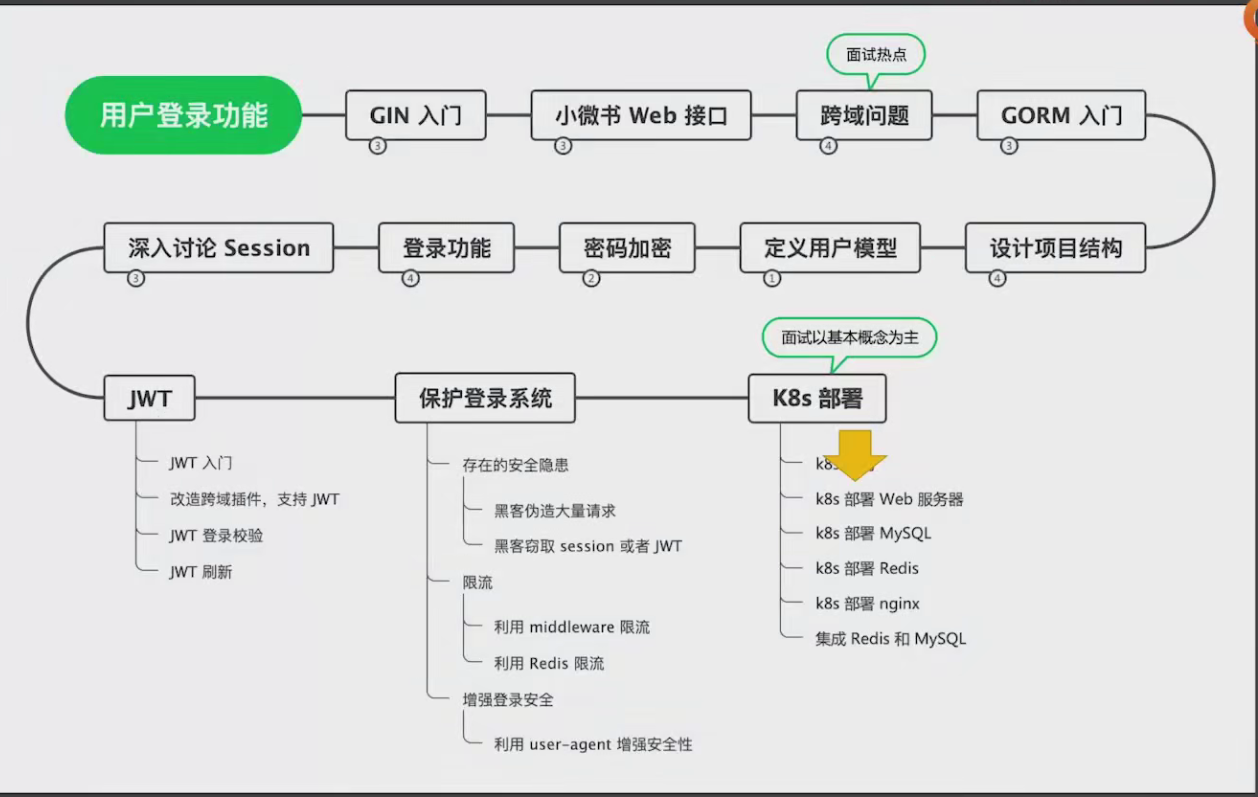
部署方案
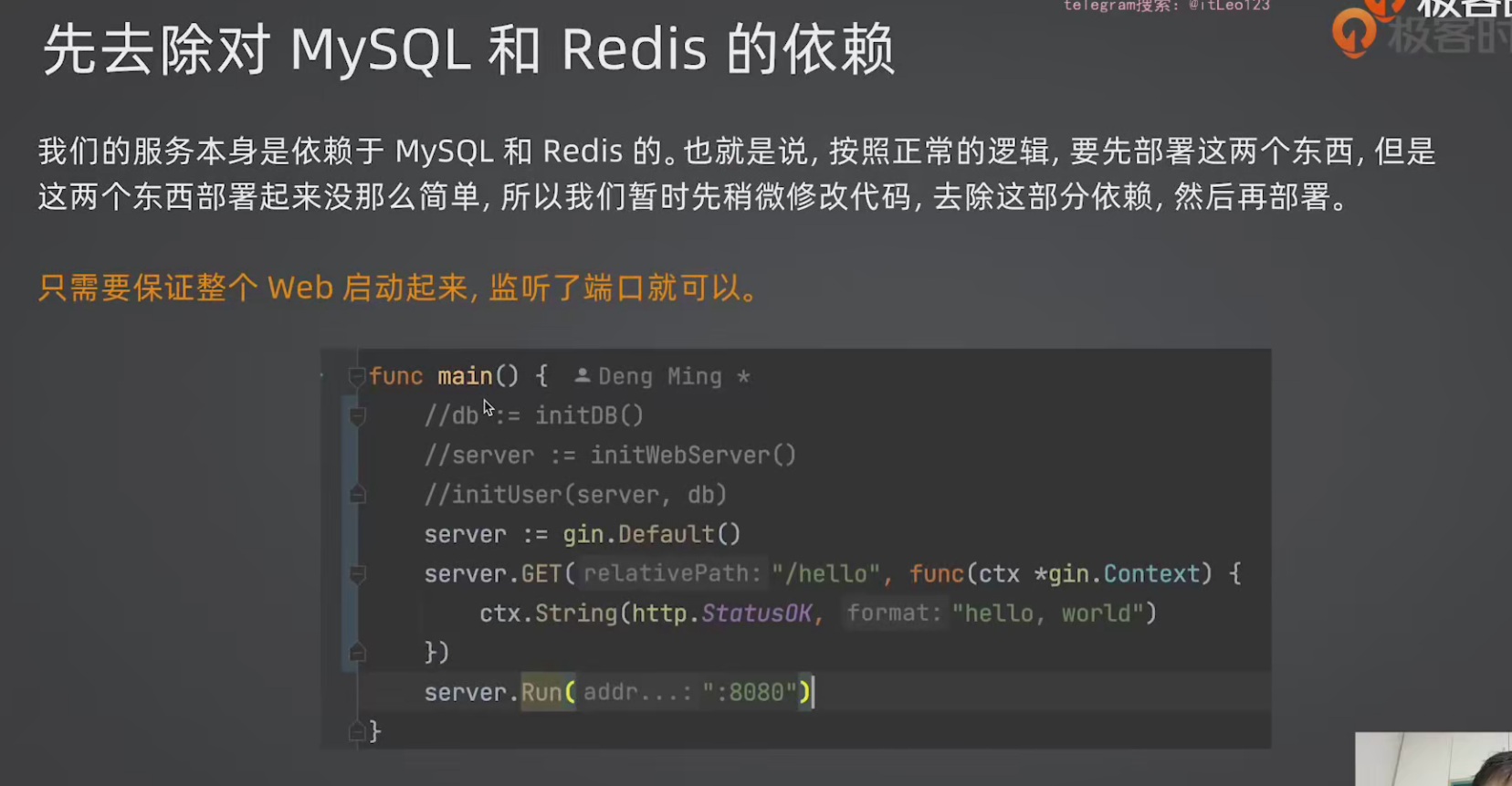
1 | //main.go |
K8s 部署 MySQL 和 Redis 比较复杂(涉及 PV/PVC/ConfigMap),第一次部署时可以先去掉代码里对 MySQL 和 Redis 的依赖,只保证 Web 服务能启动、监听端口即可。后续再慢慢加回来。
准备K8s容器镜像

dockerfile文件:打包
在webook目录下
核心作用:把你本地编译好的 Go 可执行文件打包进一个 Ubuntu 系统镜像里,让它能在 Docker 容器中运行。
1 | # 1. 指定基础镜像:使用 Ubuntu 20.04 LTS 作为容器运行环境。 |
无注释版本
1 | FROM ubuntu:20.04 |
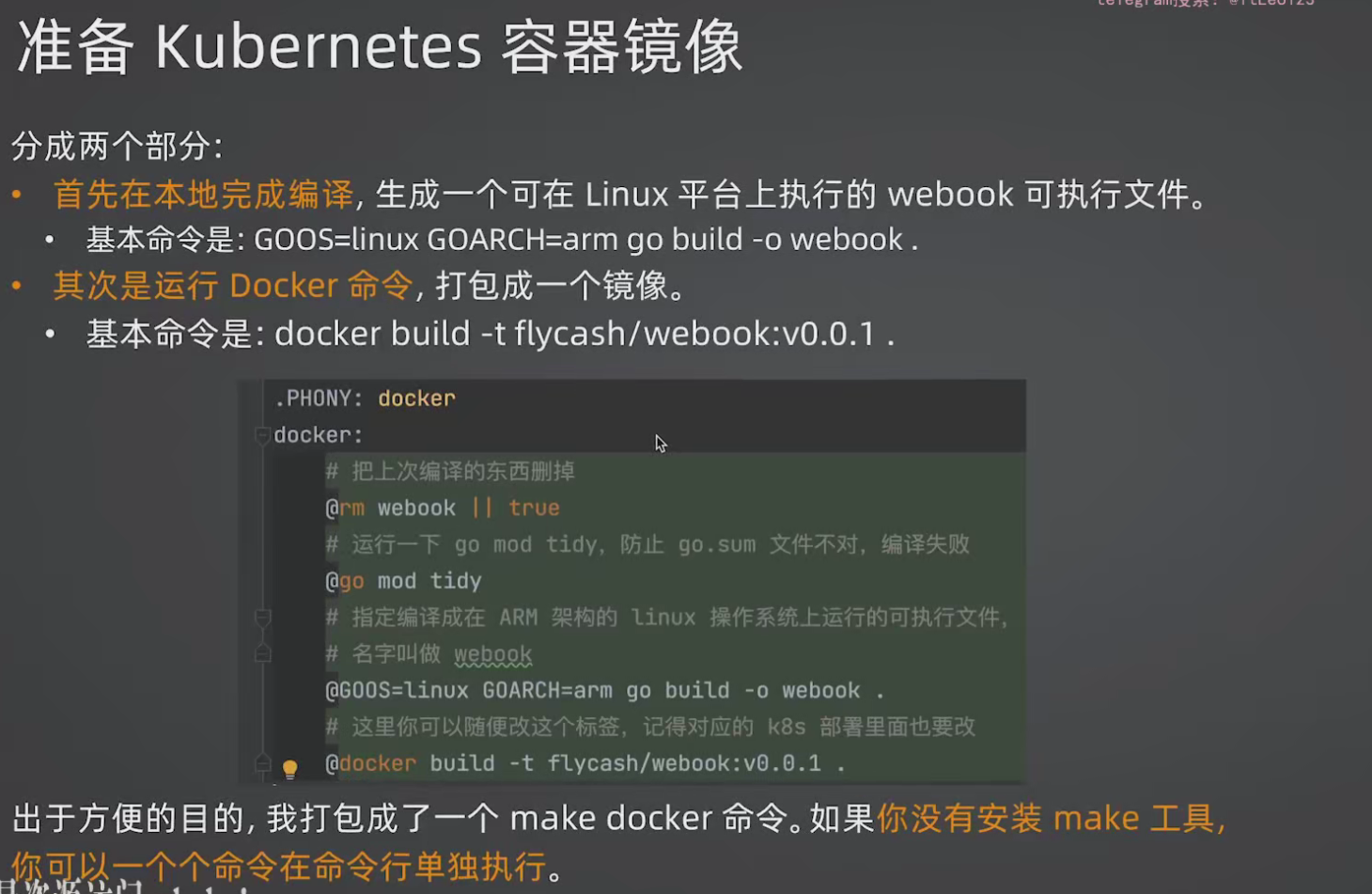
交叉编译:为 Linux 编译 Go 程序
为什么需要?
开发用 Mac/Windows,服务器跑 Linux。Go 天生支持交叉编译
1 | #在webook目录下输入这个命令 |
| 环境变量 | 含义 | 常见值 |
|---|---|---|
GOOS |
目标操作系统 | linux, darwin, windows |
GOARCH |
目标 CPU 架构 | amd64, arm64 |
为什么不在 Docker 里编译?——Docker 里编译很慢。正常是 CI(持续集成)过程编译好,再打包进镜像。
1 | #windows下输入以下命令 |
1 | PS E:\go_learning\webook_project\webook> $env:GOOS="linux" |
这个报错是因为尝试编译 ARM 架构 的 Linux 程序,而 Windows 系统上的 gcc 编译器不支持生成 ARM 代码。
Go 在编译时如果代码中用到了 cgo(即调用了 C 语言库),就需要调用宿主机的 C 编译器(gcc)来编译 C 部分。而 Windows 上的 gcc(通常是 MinGW)是为 x86/x64 设计的,不支持 ARM 的 -marm 选项,所以报错。
解决方案:禁用 cgo
如果不需要 C 语言依赖(绝大多数 Go 项目都不用),可以直接禁用 cgo,让 Go 使用纯 Go 编译,这样就绕过了 gcc。
1 | $env:CGO_ENABLED=0 |
这样应该就能成功生成 ARM 版本的 Linux 可执行文件。
打包镜像
在webook目录下执行以下命令:
1 | docker build -t darling/webook:v0.0.1 . |
得到如下图所示的最后一行的darling/webook,这个darling是标签,可以自己输
Makefile:一键构建
1 |
|
这是第一次写的,还是windows版本,这根本运行不了
1 |
|
这是linux版本的makefile
执行make docker命令,就可以删除原来的webook,重新构建一个webook
要注意:
1.在windows下执行的时候,golang ide里面的命令行powershell是不行的,得去webook目录下打开git bash,是模拟的linux环境,然后执行make docker
2.要记得写CGO_ENABLED=0,原因和上面交叉编译的原因一样的
2.4 编写Deployment
1.编写deployment.yaml文件
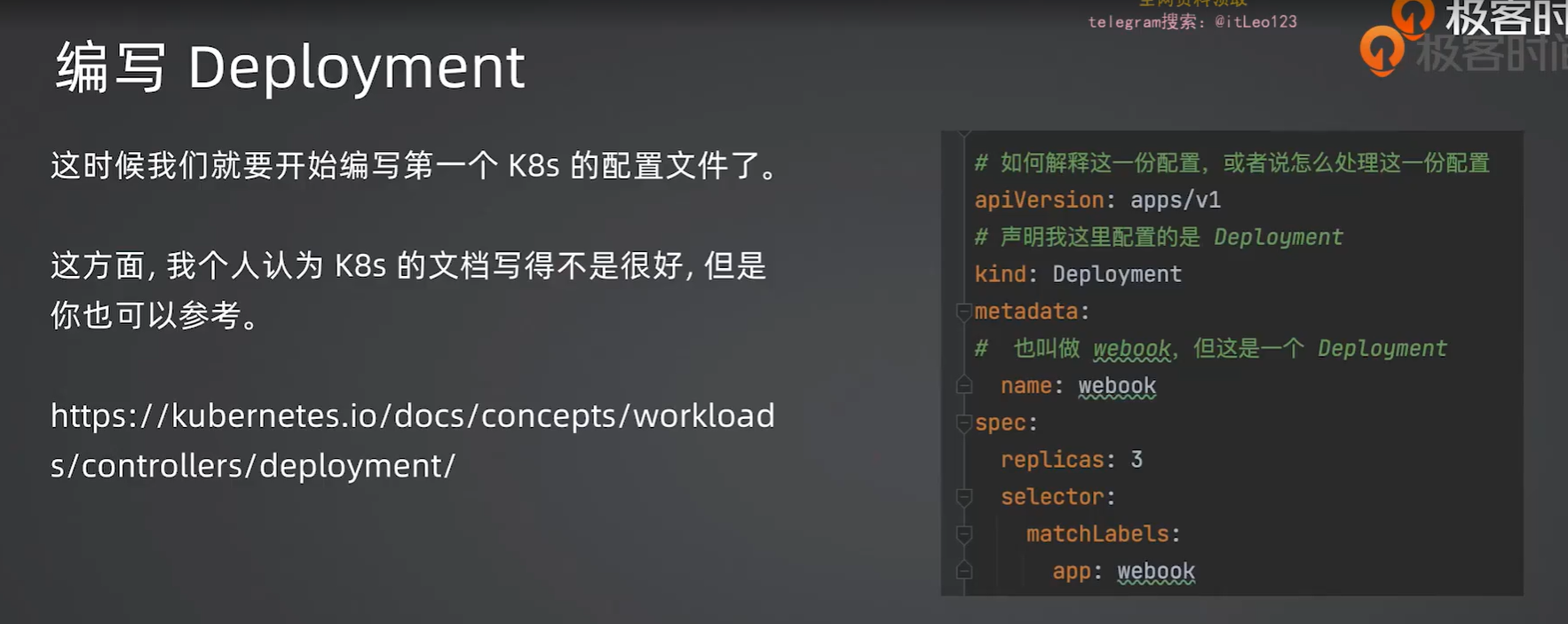

1 | # API 版本:apps/v1 是 Kubernetes 中 Deployment 资源的稳定版本 |
无注释版本
1 | apiVersion: apps/v1 |
注意:
1.第八行selector的 app: webook一定要和第16行的webook是对应的
selector 与 template.metadata.labels 必须匹配
- Kubernetes 的工作机制:Deployment 本身不直接管理 Pod,而是通过标签选择器(selector)来“认领”带特定标签的 Pod。当 Deployment 创建或更新时,它会根据 selector 查找所有带有
app: webook标签的 Pod,并将它们视为自己的“手下”,负责维护它们的副本数量、执行滚动更新等。 - 如果不匹配:Deployment 创建时,API Server 会校验 selector 是否匹配 template 中的 labels,如果不匹配则直接报错(
selector does not match template labels)。即使强行忽略,Deployment 也找不到自己该管理哪些 Pod,导致无法工作。
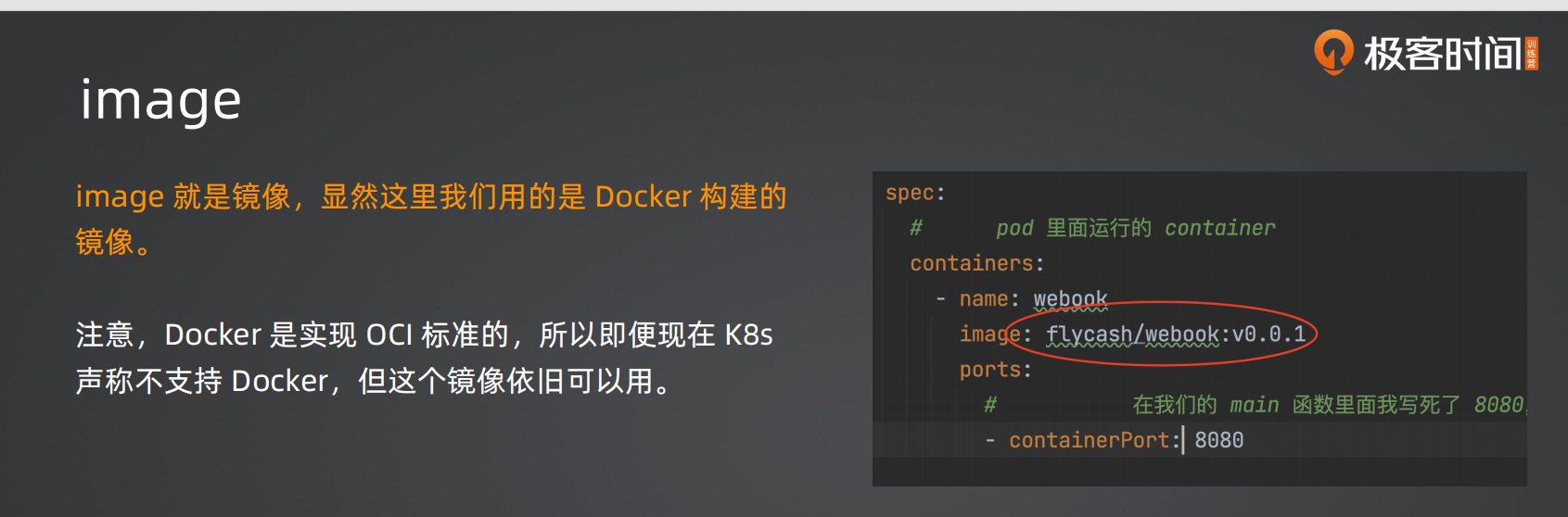
2.ports的9090要和main函数里面的server.Run(“:9090”)这个要对应上
- 这是一个声明性配置:
containerPort并不会实际改变容器内的端口绑定,它只是告诉 Kubernetes“这个容器会监听 9090 端口”。这个信息主要用于:- 当创建 Service 时,可以通过
targetPort: 9090将流量转发到容器的正确端口。 - 便于其他开发者或运维人员了解该服务提供的端口号。
- 当创建 Service 时,可以通过
- 如果不一致:虽然容器仍能正常运行(因为程序监听的是 9090,而
containerPort只是一个声明),但如果你配置 Service 转发到 9090 而程序实际监听 8080,那么流量就会转错,导致服务不可达。因此,保持一致是最佳实践,避免后续配置错误。
2.验证yaml文件
1 | # 1. 根据 YAML 文件创建或更新 Kubernetes 资源(这里是 Deployment) |
1 | kubectl apply -f k8s-webook-deployment.yaml |
1 | darling123456 MINGW64 /e/go_learning/webook_project/webook (week3) |
执行上面这3个命令出现差不多的结果就是这个yaml没写错
3.K8s 的核心设计:声明式驱动

apiVersion 的作用:告诉 K8s “这份配置该用什么版本的规范来解读”。不同 apiVersion 对应不同的字段结构和行为。写 YAML 时 GoLand 会自动提示正确的 apiVersion。
- “声明式” vs “命令式”:
- 命令式(你日常操作):你告诉电脑“怎么做”。比如:
go build -o webook .(编译)→docker build ...(打包)→kubectl apply ...(部署)。每一步你都要亲自指挥。 - 声明式(K8s 的做法):你只告诉 K8s“最终要什么”。比如你在 YAML 里写
replicas: 3,K8s 看了之后,自己去判断现在有几个 Pod,少了就创建,多了就删除,你不需要告诉它怎么创建、怎么删除。
- 命令式(你日常操作):你告诉电脑“怎么做”。比如:
- 配置驱动/元数据驱动:一切皆以 YAML 配置为准。K8s 的“大脑”(控制器)就像一个永不停歇的监控器,不停地扫描这些配置,确保现实状态无限趋近于配置里的期望状态。
4.各个字段详细含义



2.5 编写service
1.编写service.yaml

1 | # API 版本:v1 是 Kubernetes 核心 API 组,用于 Service 资源 |
1 | apiVersion: v1 |
注:targetport要和deployment.yaml里面的containerPort要对应上
2.启动服务(验证)
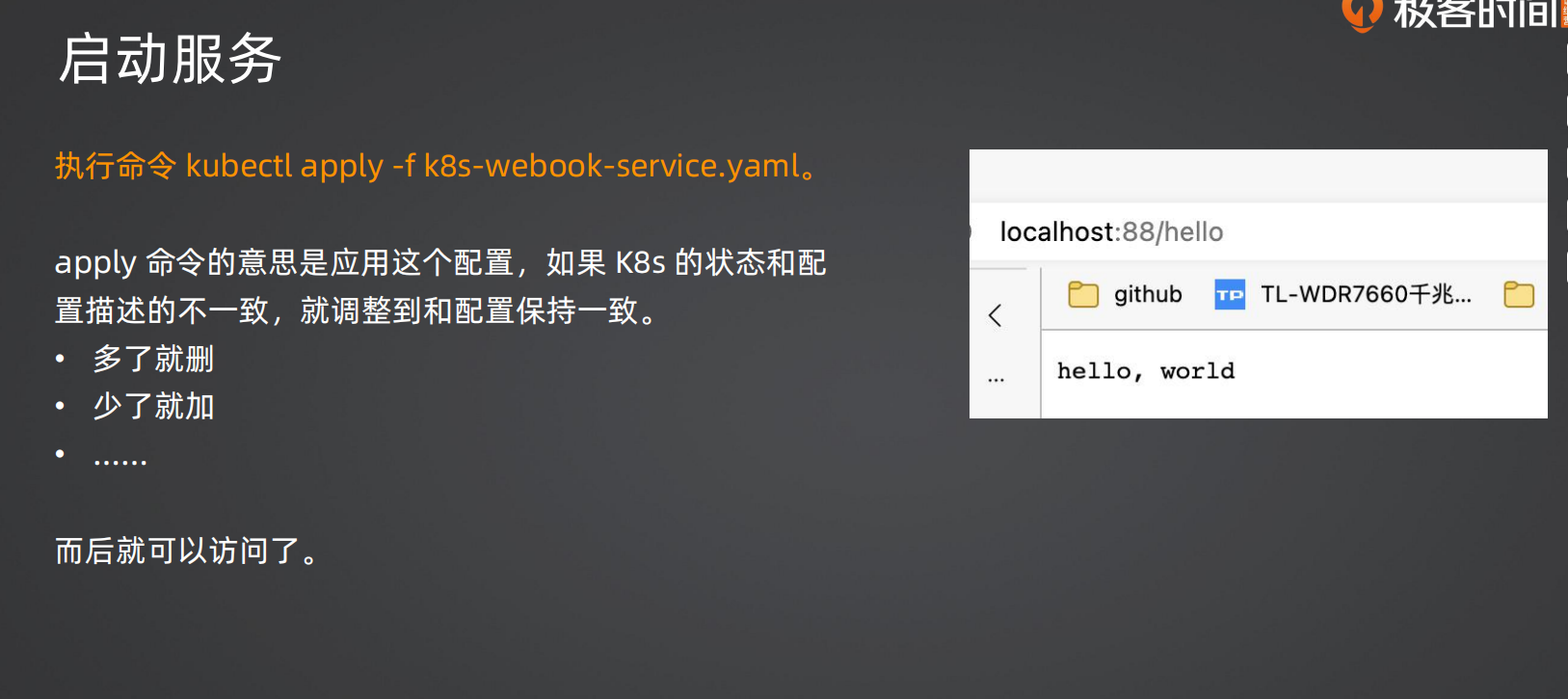
1 | darling123456 MINGW64 /e/go_learning/webook_project/webook (week3) |
执行后访问如下网站
1 | http://localhost:80/hello |

至此就算配置成功了
3.可能遇到的问题
访问http://localhost:80/hello这个网址的时候没有成功
那你要看看,spec的type一定要是LoadBalancer,而不能是NodePort,不然就会访问失败
4. Service 的三种类型
Service 主要有三种类型,区别在对外暴露的方式。
| 类型 | 访问方式 | 使用场景 |
|---|---|---|
| ClusterIP | 只能在集群内部访问 | 服务间互相调用(如 Web 调 MySQL) |
| NodePort | 通过节点 IP + 端口从外部访问 | 开发调试,简单暴露服务 |
| LoadBalancer | 云厂商分配公网 IP,自动负载均衡 | 生产环境对外暴露 |
Docker Desktop 内置的 K8s 支持 LoadBalancer,会自动分配
localhost可访问的端口。
Service 怎么找到 Pod? 通过 selector 标签匹配。Service 持续监听带匹配标签的 Pod,自动负载均衡——Pod 挂了、重建了、IP 变了,Service 都能自动感知。
2.6 总结
1. Go 源码 → 二进制文件
- 写了
main.go,监听9090端口,注册/hello路由。 - 执行
make docker→ 在 Windows 上交叉编译出 Linux ARM 可执行文件webook。 CGO_ENABLED=0→ 纯静态编译,不依赖 C 库,能直接在 Ubuntu 容器里跑。
2. 二进制 → Docker 镜像
- Dockerfile 做了 3 件事:
- 拉取
ubuntu:20.04作为基础镜像; - 把
webook复制到/app/webook; - 容器启动时自动执行
/app/webook。
- 拉取
- 最终打成一个镜像:
darling/webook:v0.0.1,存在本地 Docker 仓库里。
3. 镜像 → Kubernetes Pod
- 执行
kubectl apply -f k8s-webook-deployment.yaml,提交 Deployment 给 K8s。 - K8s 拉取本地镜像,创建 3 个 Pod 副本,每个 Pod 里跑着你的 Go 服务(监听
9090)。 kubectl get pods显示Running→ 服务已正常启动。
4. Service 暴露 Pod(关键!)
- 执行
kubectl apply -f k8s-webook-service.yaml,创建 Service。 - 关键配置:
type: LoadBalancer→ Docker Desktop 会把 Service 的端口直接绑定到宿主机localhost。port: 80→ 浏览器访问http://localhost时直接命中,不需要带端口号。targetPort: 9090→ 流量转发到 Pod 内 Go 程序监听的端口。
- Endpoints 控制器通过
selector: app: webook找到 3 个 Pod,绑定它们的 IP 和9090端口。
5. 最终访问成功
- 在浏览器输入
http://localhost/hello。 - 流量直达 Service 的 80 端口 → 负载均衡到任意一个 Pod 的 9090 端口 → Go 程序处理请求 → 返回
"你好,你来了"。
2.7 概念速查
| 概念 | 一句话 |
|---|---|
| 交叉编译 | GOOS/GOARCH 指定目标平台,编译 Linux 可执行文件 |
| K8s 声明式驱动 | 用户写 YAML 声明”我要什么”,K8s 自动执行”怎么做到” |
| Pod | K8s 最小部署单元,一个 Pod 跑一个实例 |
| Deployment | 管理 Pod 的控制器,保证 Pod 数量正确 |
| Service | Pod 的固定入口,selector 标签匹配 + 负载均衡 |
apiVersion |
告诉 K8s 用哪个版本的 API 规范解读 YAML |
selector.matchLabels |
Deployment 通过标签找到它管理的 Pod |
| ClusterIP / NodePort / LoadBalancer | Service 三种暴露类型:内网 / 节点端口 / 公网 LB |
三、K8s 部署 MySQL
3.1 核心问题:数据不能丢
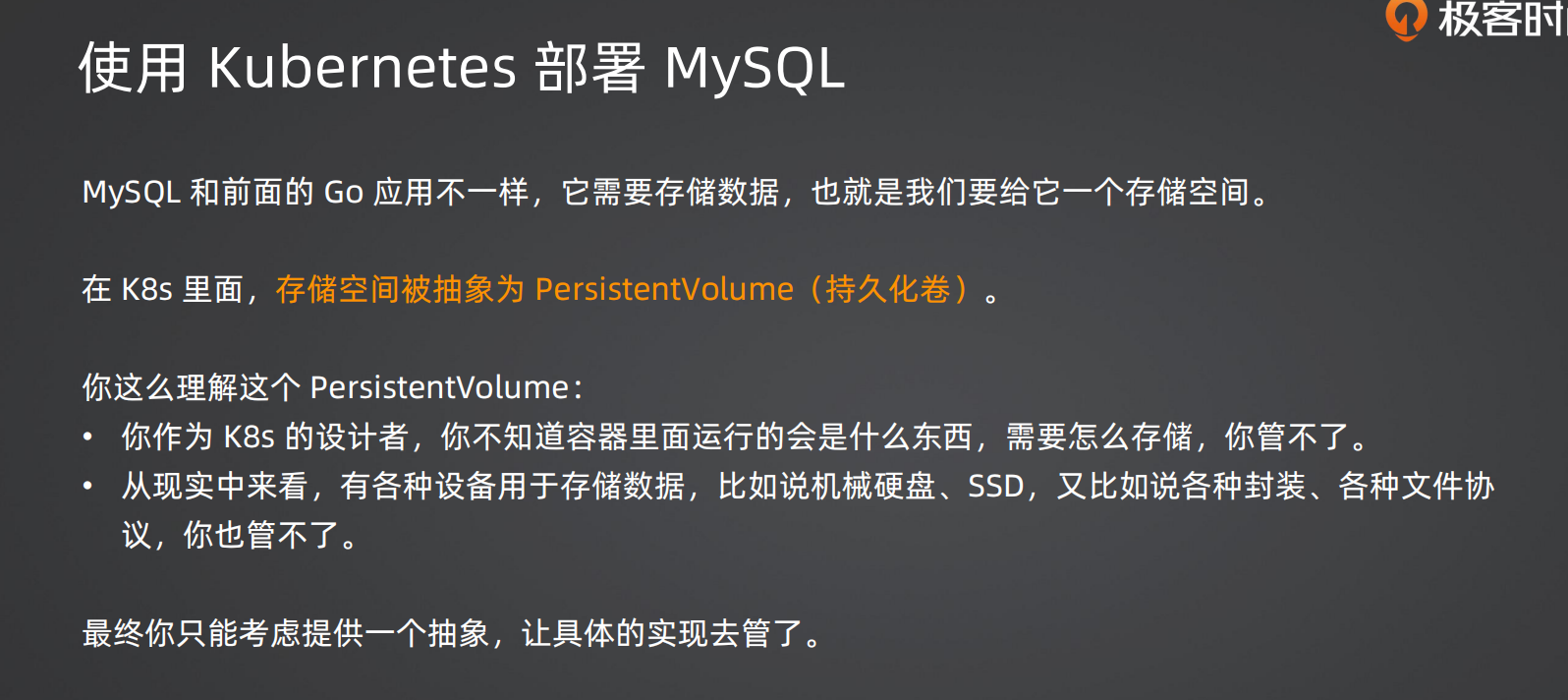
Pod 是临时的——挂了重建之后,里面的数据全没了。MySQL 必须用 PersistentVolume(PV) 把数据持久化到宿主机。
3.2 mysql-deployment.yaml 和 service.yaml 基础版本

1 | kubectl apply -f k8s-webook-deployment.yaml |
1 | kubectl apply -f k8s-webook-service.yaml |
1 | # deployment.yaml |
1 | #service.yaml |
1 | //注:这是在docker-compose.yaml中的环境变量,也就是root用户密码要在上面的deployment.yaml中配置 |
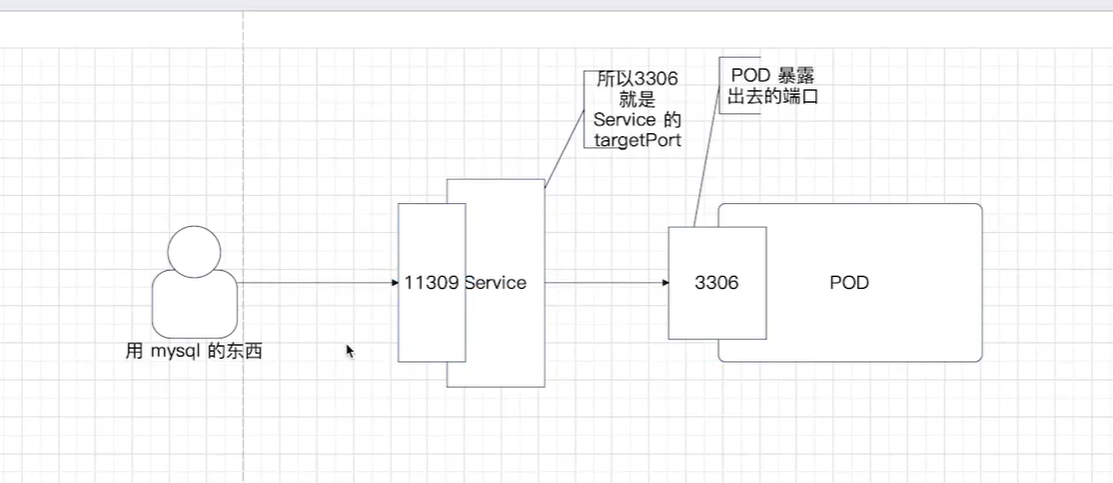
理解这几个端口号:
golang中数据库配置
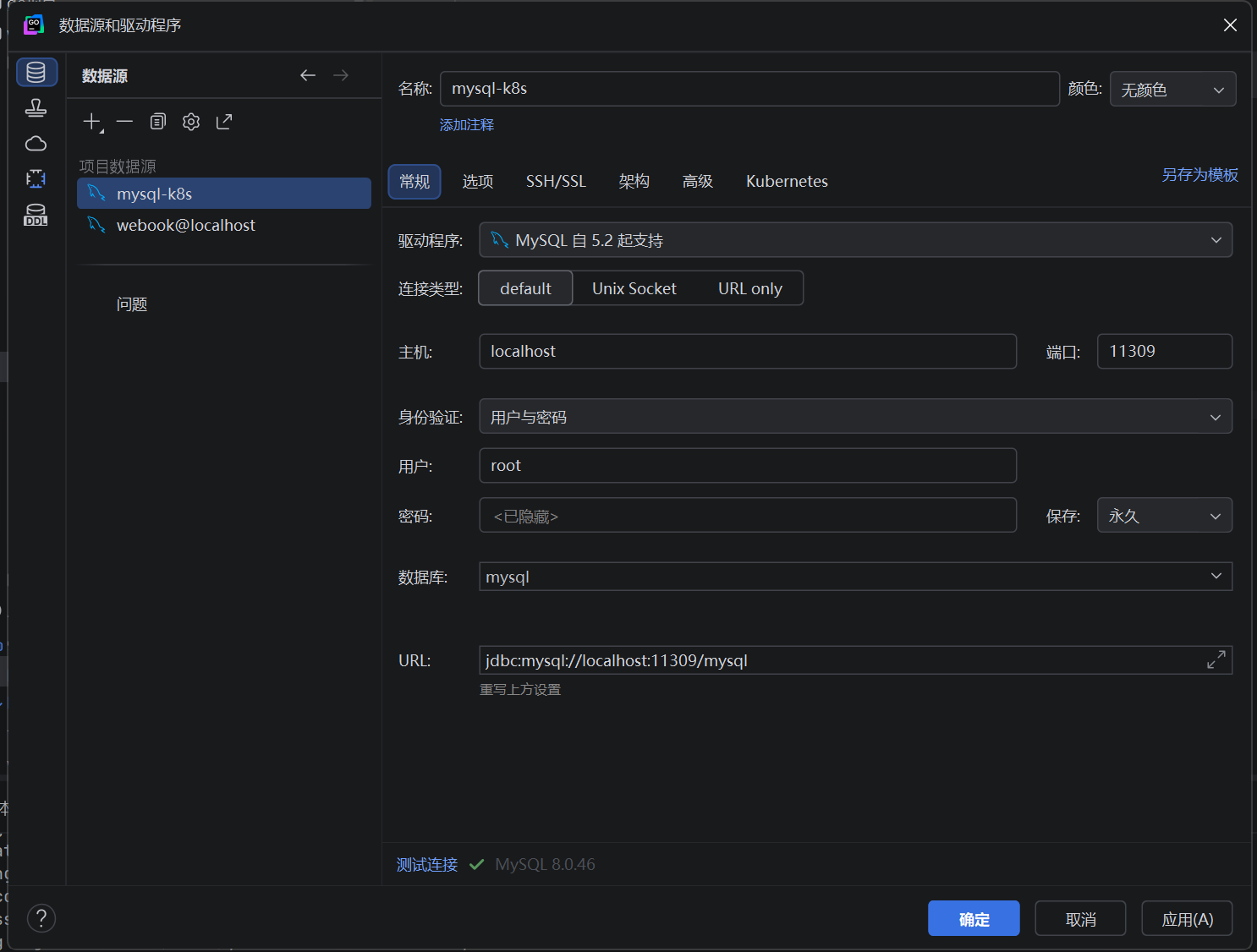
进入数据库之后,再自己创建一个webook的数据库然后修改属性
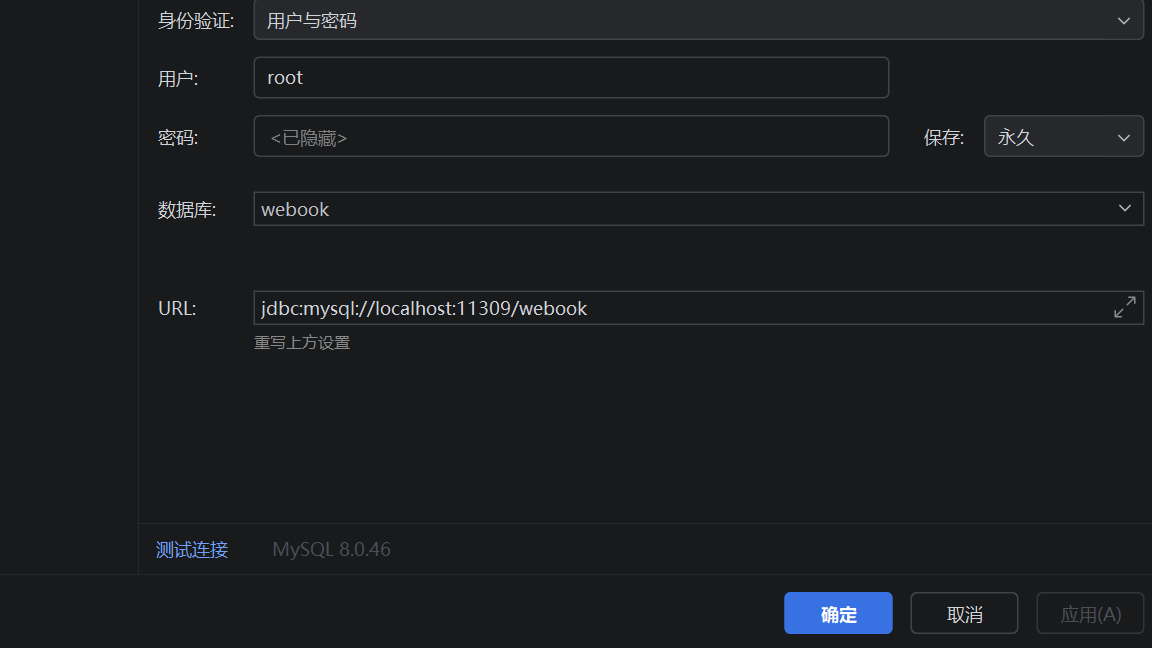
当前还没有持久化,如果你直接down了,那下次还得换成mysql这个数据库而不是webook这个数据库,因为down之后所有的资源都没有了,包括创建的webook数据库。
3.3 加入持久化内容

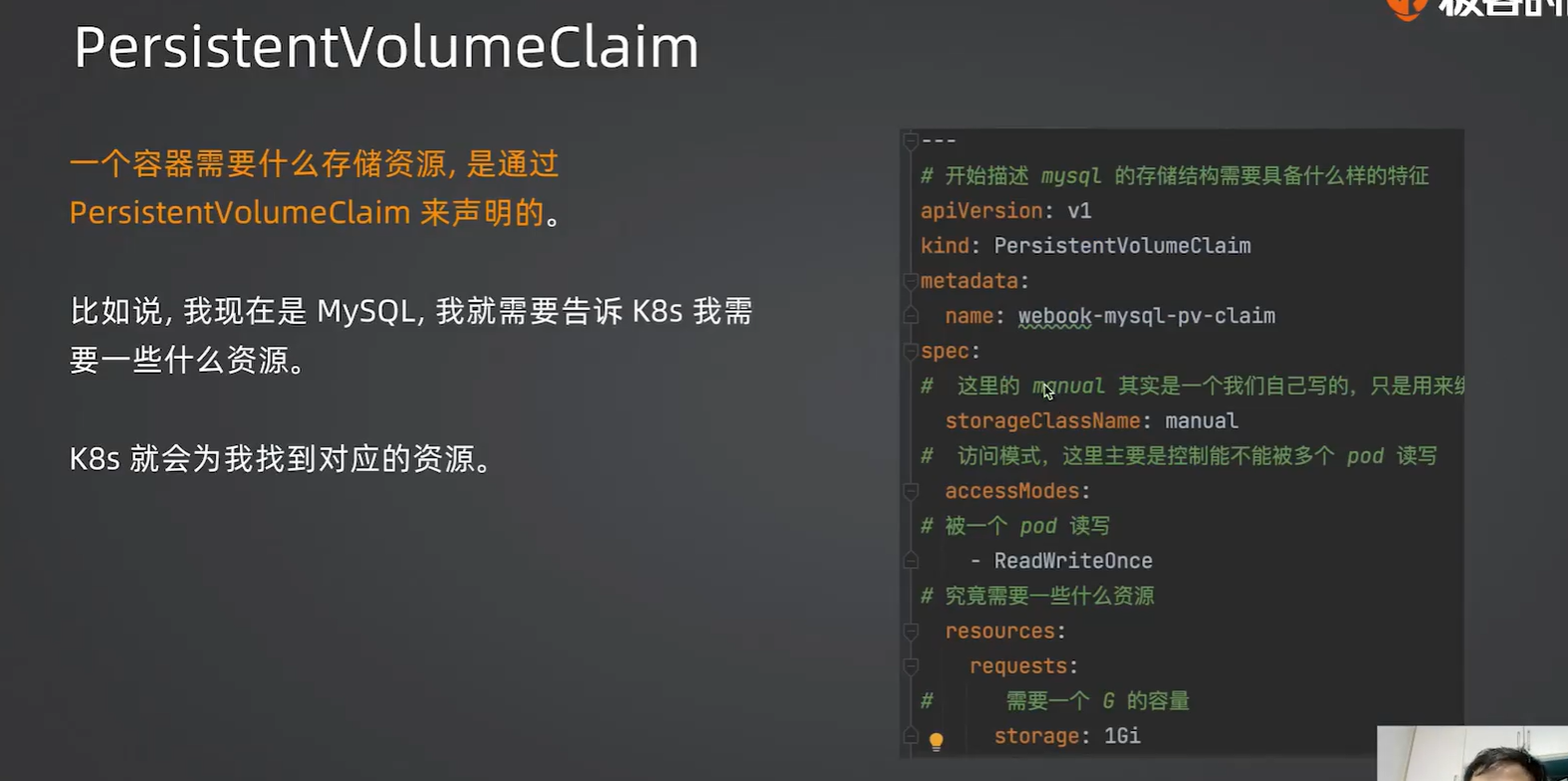

mysql storage、PV、PVC关系
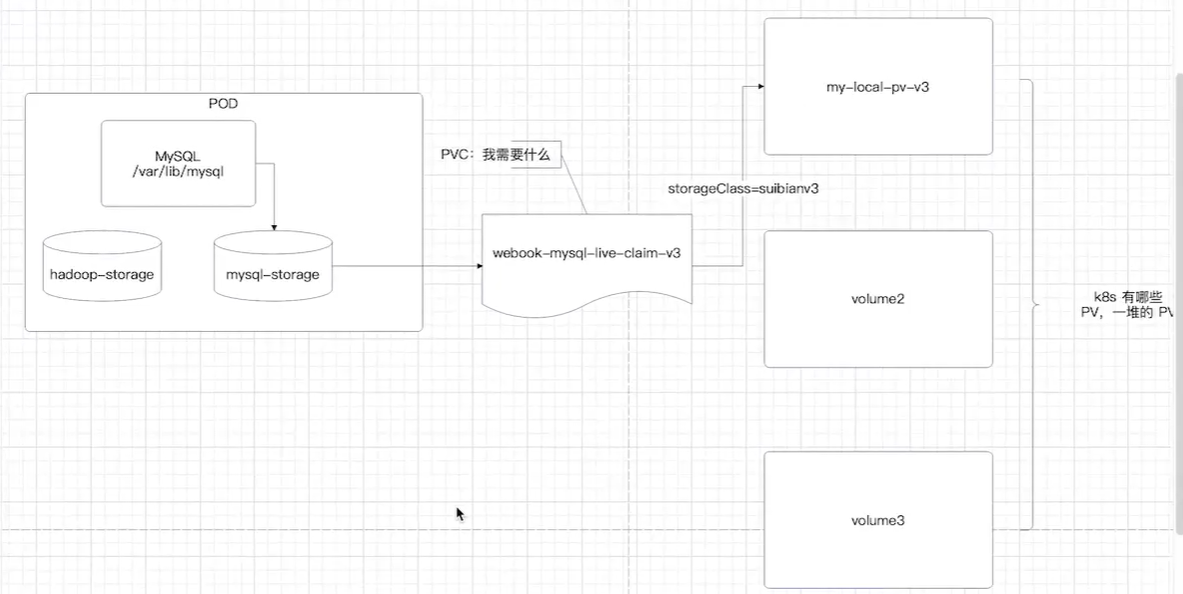
组件关系详解(完整版)
第一个问题:这五个东西到底是什么?
为了彻底记住,用“搬家”来类比:
| 组件 | 搬家类比 | 在 K8s 里是什么 |
|---|---|---|
/var/lib/mysql |
你家的卧室:MySQL 这个“人”只住这间房,只把东西放这里 | MySQL 容器内部的数据目录,MySQL 进程写死的路径,改不了 |
mysql-storage |
卧室门口的标签:“这是卧室A”,方便工人(Pod)认 | Deployment 里起的一个名字,用来在 Pod 内部标识这个存储槽位 |
| PVC | 搬家合同:写明了“我要一个 1GB 的柜子,要能读写” | 存储申请单,描述了需求(多大、什么类型、什么速度) |
| PV | 仓库里的柜子:已经存在、贴上标签“1GB、可读写”的实体柜子 | 集群里已准备好的存储资源,管理员提前创建的 |
宿主机目录(/mnt/live) |
仓库本身:柜子摆放在这个仓库里,数据最终存在这里 | 物理存储位置,在你的 WSL2 虚拟机硬盘上 |
第二个问题:这五层是怎么连接起来的?(数据流向)
1 | MySQL 进程 |
每一层只认识“上一层”和“下一层”,但不认识隔层的东西:
- MySQL 不知道有
mysql-storage,它只管往/var/lib/mysql写。 mysql-storage不知道有 PV,它只知道claimName指向 PVC。- PVC 不知道有宿主机目录,它只管匹配 PV。
- PV 知道有宿主机目录,因为
hostPath是它自己写的。
第三个问题:YAML 里怎么体现这些关系?
关系①:/var/lib/mysql 和 mysql-storage 的连接(在 Deployment 里)
1 | containers: |
解读:把容器内的 /var/lib/mysql“接到” Pod 里名叫 mysql-storage 的卷上。
关系②:mysql-storage 和 PVC 的连接(也在 Deployment 里)
1 | volumes: |
解读:mysql-storage 这个插槽,接的是名叫 webook-mysql-claim 的 PVC。
关系③:PVC 和 PV 的连接(靠“标签+容量”匹配)
1 | # PVC |
解读:K8s 自动匹配,找到这三个条件都符合的 PV,然后 PVC 和 PV 绑定。
注意:PVC 里没有写 claimName 指向 PV,因为它们是自动匹配绑定的,而不是手动指定名字。你在 kubectl get pvc 里看到的 VOLUME 列,是绑定成功后 K8s 自动填上去的。
第四个问题:为什么需要这么多层?直接让 Pod 用 PV 不行吗?
不行。原因有两点:
解耦应用和管理员:
- 开发者(写 Deployment 的人)只需要写 PVC,说“我要 1GB”。
- 管理员(管集群的人)提前准备好 PV,说“我这里有一堆 1GB、2GB、5GB 的存储”。
- 双方不用商量具体名字,K8s 自动撮合。
Pod 重建时数据不丢:
- Pod 可以被删掉重建(IP、名字都变了),但 PVC 还在。
- 新 Pod 只要用同一个 PVC 名字,就能找到原来绑定的 PV,数据接着用。
一句话总结
/var/lib/mysql是 MySQL 写数据的窗口,mysql-storage是 Pod 里接这个窗口的插槽,PVC 是申请单,PV 是集群里的现房,宿主机/mnt/live是物理位置。数据从 MySQL 出发,一路经过这五个站,最终存到你的硬盘上。Pod 重启后,走同样的路,就能找回原来的数据。
对应关系速查表(写 YAML 时对着检查)
| 要检查的匹配 | 位置 A | 位置 B | 不匹配的后果 |
|---|---|---|---|
PVC 和 PV 的 storageClassName |
pvc.spec.storageClassName |
pv.spec.storageClassName |
PVC 一直 Pending,找不到 PV |
PVC 和 PV 的 accessModes |
pvc.spec.accessModes |
pv.spec.accessModes |
绑定失败 |
| PVC 申请的容量 ≤ PV 的容量 | pvc.spec.resources.requests.storage |
pv.spec.capacity.storage |
绑定失败(容量不够) |
Deployment 的 claimName |
volumes.persistentVolumeClaim.claimName |
PVC 的 metadata.name |
Pod 找不到 PVC,启动失败 |
Deployment 的 volumeMounts.name |
volumeMounts.name |
volumes.name |
容器目录找不到对应的卷,挂载失败 |
Deployment 和 Service 的 selector |
spec.selector.matchLabels |
spec.template.metadata.labels |
Deployment 管不了 Pod,Service 找不到 Pod |
具体的配置文件
1 | # ============================================================ |
不带注释版本
1 | # k8s-mysql-pv.yaml |
1 | # k8s-mysql-pvc.yaml |
1 | # k8s-mysql-deployment.yaml |
1 | # k8s-mysql-service.yaml |
对比:
| 序号 | 匹配点 | 具体位置(文件及字段) | 说明 |
|---|---|---|---|
| ① | PVC 引用 PV | pvc.spec.storageClassName: suibian ↔ pv.spec.storageClassName: suibian |
必须完全一致,否则 PVC 找不到对应的 PV,会一直 Pending。 |
| ② | 存储容量匹配 | pvc.spec.resources.requests.storage: 1Gi ≤ pv.spec.capacity.storage: 1Gi |
PVC 申请的大小不能超过 PV 的容量,否则绑定失败。 |
| ③ | 访问模式匹配 | pvc.spec.accessModes: ReadWriteOnce ↔ pv.spec.accessModes: ReadWriteOnce |
必须完全一致,否则无法绑定。 |
| ④ | Deployment 引用 PVC | deployment.spec.template.spec.volumes.persistentVolumeClaim.claimName: webook-mysql-claim ↔ pvc.metadata.name: webook-mysql-claim |
名字必须完全一致,Pod 才能找到对应的 PVC。 |
| ⑤ | Volume 名称对应 | deployment.spec.template.spec.containers.volumeMounts.name: mysql-storage ↔ deployment.spec.template.spec.volumes.name: mysql-storage |
必须在同一个 Deployment 内部匹配,把容器内的挂载点和 Pod 的存储声明连接起来。 |
| ⑥ | Service 选择 Pod | service.spec.selector.app: webook-mysql ↔ deployment.spec.template.metadata.labels.app: webook-mysql |
必须匹配,否则 Service 找不到 Pod,流量进不来。 |
| ⑦ | Deployment 选择 Pod | deployment.spec.selector.matchLabels.app: webook-mysql ↔ deployment.spec.template.metadata.labels.app: webook-mysql |
必须匹配,否则 Deployment 不知道自己该管哪些 Pod。 |
使用流程(执行顺序)
1 | # 1. 先创建存储资源(PV 和 PVC) |
3.4 验证
1 | kubectl apply -f k8s-mysql-deployment.yaml |
执行上述命令,而后去ide中连接数据,创建webook数据库并在webook数据库中建表插入数据
1 | kubectl delete deployment webook-mysql |
而后执行上面这个命令,删除配置,验证是否有持久化
1 | kubectl apply -f k8s-mysql-deployment.yaml |
再次执行命令之后,去webook数据库看看数据是不是还在,还在的话,那就说明持久化成功了
- PV 和 PVC 不需要重复 apply
- 你每次重建 Deployment 时,PV 和 PVC 如果已经存在且状态正常,是不需要重新 apply 的。直接执行
kubectl apply -f k8s-mysql-deployment.yaml就够了。 - 但如果你担心配置有变化,重新 apply 也无害(K8s 会显示 “unchanged”)。
- 你每次重建 Deployment 时,PV 和 PVC 如果已经存在且状态正常,是不需要重新 apply 的。直接执行
- 持久化验证的关键文件
- 确保你的 PVC 的
accessModes和 PV 匹配(都是ReadWriteOnce),否则绑定会失败。 - 你的
hostPath: /mnt/live如果是在 WSL2 环境中,确认这个目录存在且 MySQL 有写入权限。
- 确保你的 PVC 的
3.5 验证过程中遇到的bug
好的,我把这个Bug的来龙去脉、解决步骤和底层原理,整理成一份结构清晰的“Bug分析报告”,你可以直接复制到笔记里。
Bug 描述(问题是什么?)
现象:
按照标准的 PV、PVC、Deployment 部署了 MySQL,但每次删除 Pod 或重建 Deployment 后,之前写入的数据都会丢失,持久化完全没有生效。
表面症状:
kubectl get pv和kubectl get pvc都显示Bound(绑定成功),状态正常。- Pod 能正常启动,
kubectl exec进入 MySQL 也能写入数据。 - 但是,一旦
kubectl delete pod,新 Pod 启动后,SHOW DATABASES;发现只剩下默认的系统库,之前建的库和表全没了。
最迷惑的地方:
PV 和 PVC 都显示绑定成功了,看起来一切正常,但数据就是存不住。
怎么解决的?(修复操作)
只修改了 k8s-mysql-deployment.yaml 文件中的一处配置:
修改前(错误):
1 | volumeMounts: |
修改后(正确):
1 | volumeMounts: |
改完之后,重新 kubectl apply -f k8s-mysql-deployment.yaml,再删 Pod 重建,数据就完好无损了。
解决的原理(为什么这样就能行?)
要理解这个原理,需要理清三个关键点:
- MySQL 容器内部有固定的“数据存放点”
- MySQL 官方 Docker 镜像在启动时,其进程(
mysqld)被写死为:所有数据文件(表、索引、日志等)默认写入容器内的/var/lib/mysql目录。 - 无论你挂载什么卷,MySQL 进程本身只认这一个路径,它不可能把数据写到
/mysql或/data里。
- 挂载(mountPath)的本质是“目录覆盖”
- 当你在 Deployment 中设置
mountPath: /mysql时,K8s 确实把存储卷挂载到了容器的/mysql目录。 - 这意味着:往
/mysql里写数据,会进入存储卷(PV);往/var/lib/mysql里写数据,依然写在容器的临时存储里。 - 因为 MySQL 进程只往
/var/lib/mysql写,所以存储卷(PV)里始终是空的。数据全躺在容器的“草稿纸”上。
- Pod 删除时,容器的“草稿纸”会被清空
- Pod 被删除时,容器内的临时文件系统(
/var/lib/mysql默认就在这上面)会被彻底销毁。 - 而挂载点(PV)因为对应的是宿主机硬盘(或远程存储),独立于 Pod 生命周期,所以能持久保存。
- 修复的本质:把存储卷的挂载点(
/var/lib/mysql)精确对齐到应用程序(MySQL)实际写入数据的目录,让所有写入操作“无缝滑入”持久化存储中。
一句话总结(笔记版)
Bug 根因: mountPath 没有指向应用程序的实际数据目录,导致卷虽然挂载了,但 MySQL 并不往里面写数据。
核心解决原则: 卷挂载的 mountPath 必须等于 容器内应用程序默认的数据存储路径,而非随意指定的路径。
常见中间件数据目录速查表(补充到笔记)
| 中间件 | 容器内默认数据目录 |
|---|---|
| MySQL | /var/lib/mysql |
| PostgreSQL | /var/lib/postgresql/data |
| MongoDB | /data/db |
| Redis (持久化) | /data |
| Elasticsearch | /usr/share/elasticsearch/data |
部署任何带持久化需求的服务时,第一步先去查官方镜像文档,确认“数据写在哪”,再把
mountPath精准指向那里
3.6 其他各个字段含义
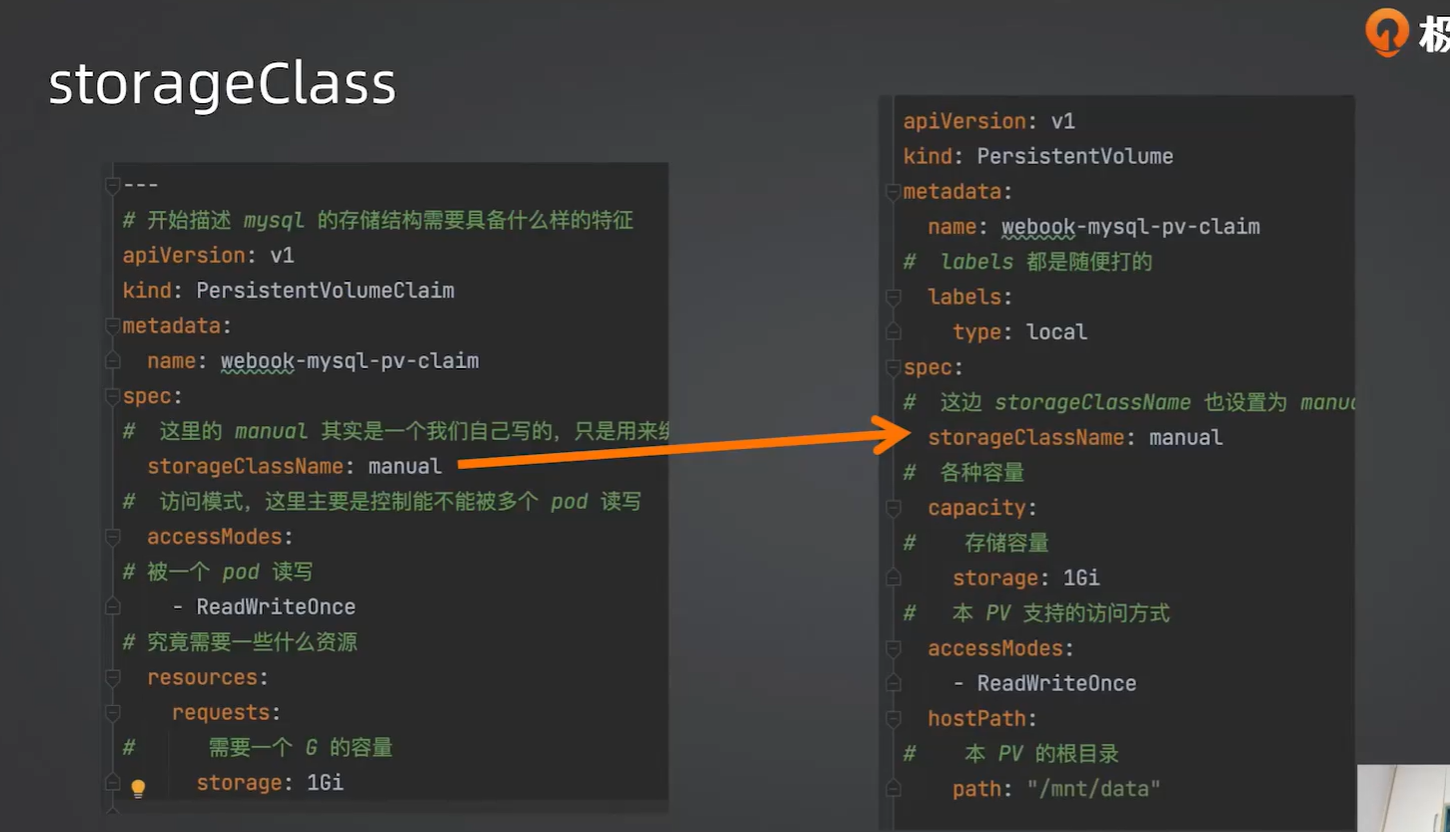
一样的话就是我这个pvc需要的你这个pv可以支持,就是匹配上了
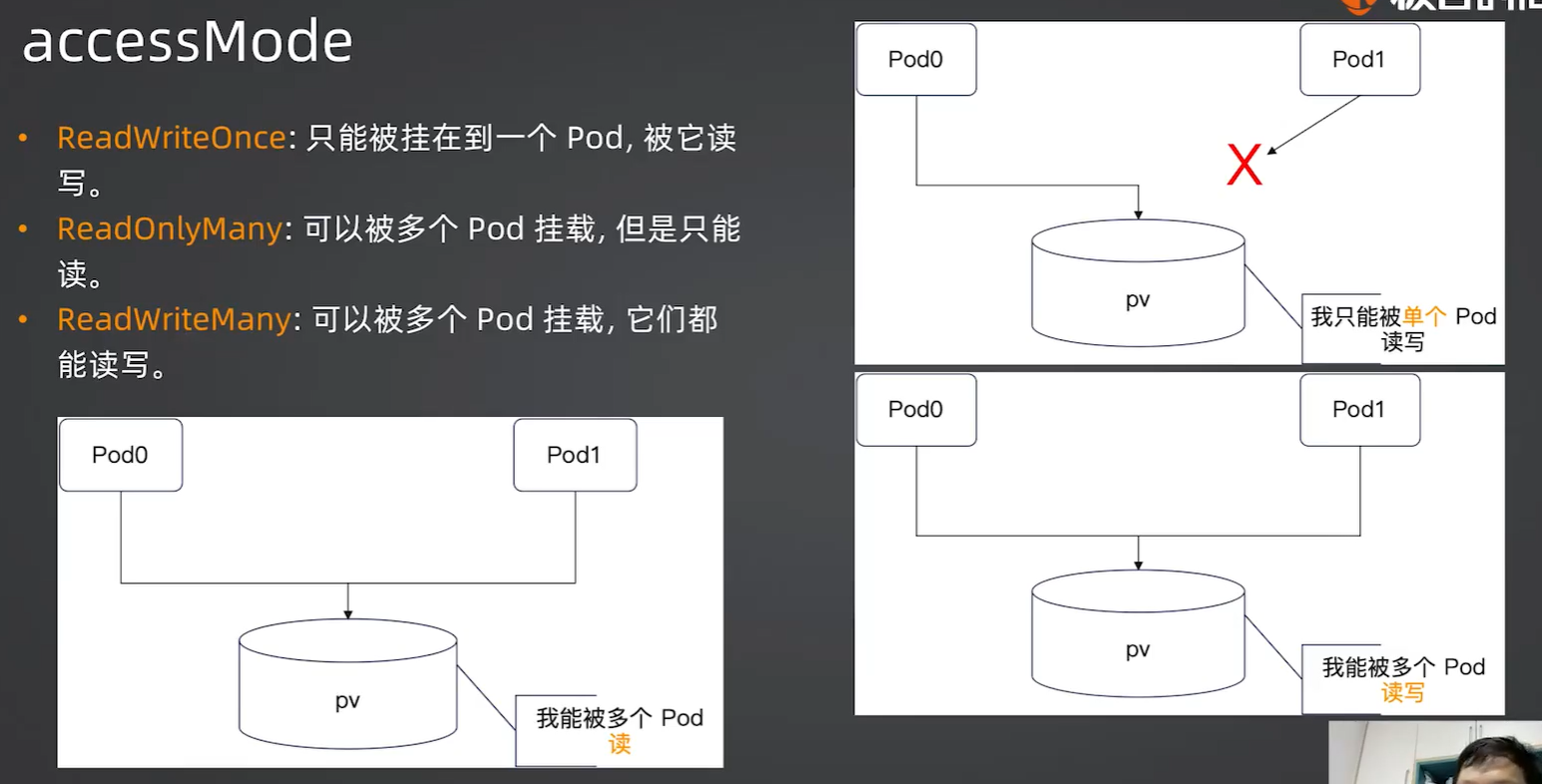
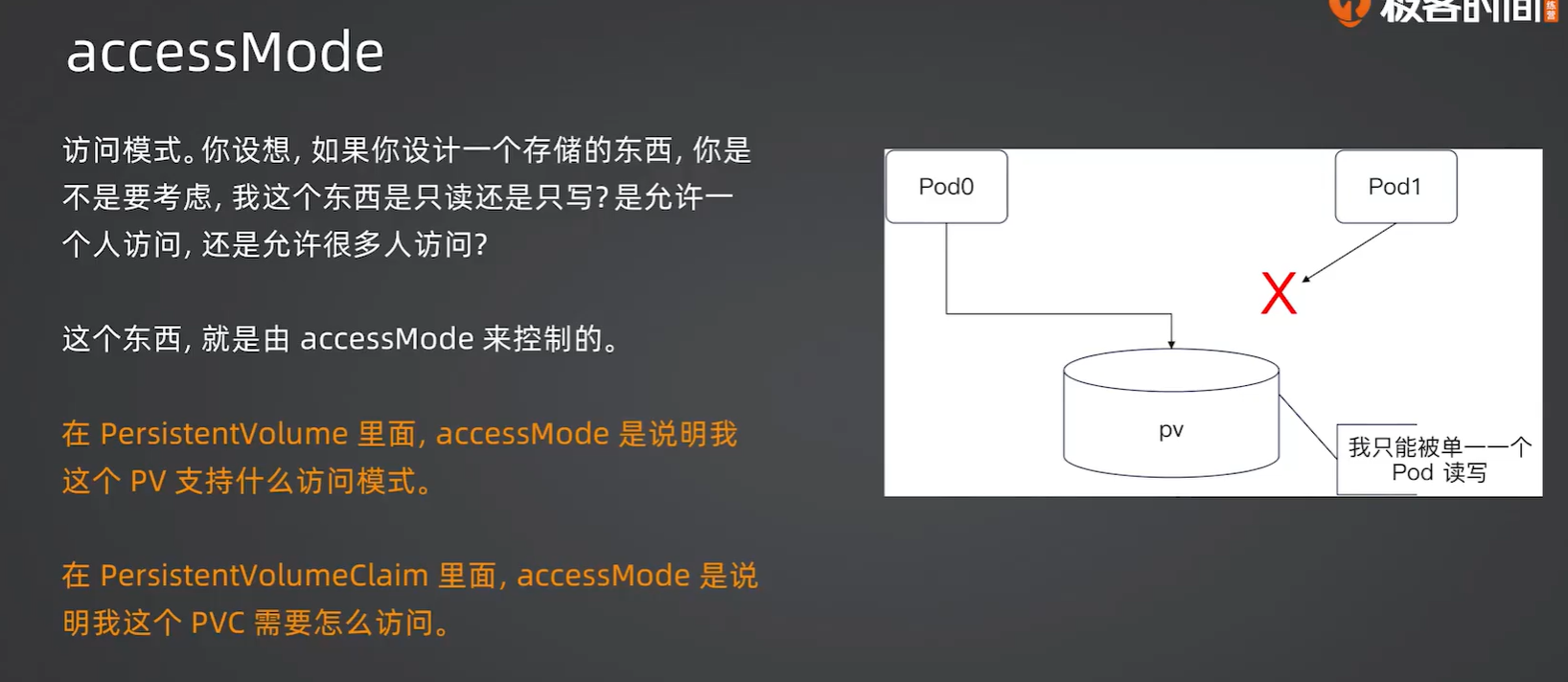
这里的一个是指一个pod,而一个pod里面可以有多个线程
四、K8s 部署 Redis
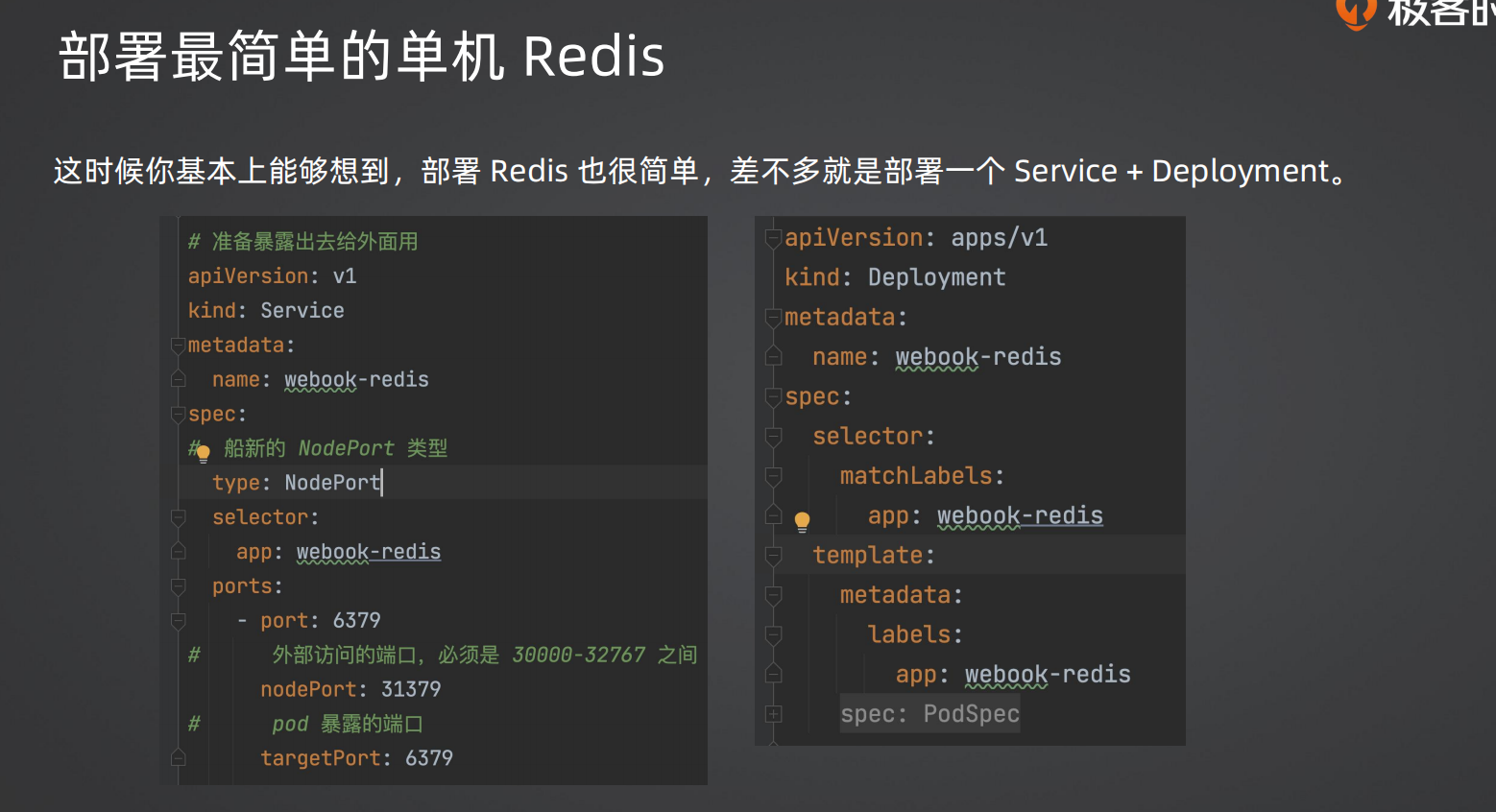
4.1 redis-deployment.yaml
1 | apiVersion: apps/v1 |
Redis 结构和 MySQL 类似——单实例 + ClusterIP。如果需要持久化也可以挂 Volume。
4.2 redis-service.yaml
1 | apiVersion: v1 |
4.3 验证
输入以下命令得到以下结果就算成功
1 | darling123456 MINGW64 /e/go_learning/webook_project/webook (week3) |
4.4 port、nodeport、targetport
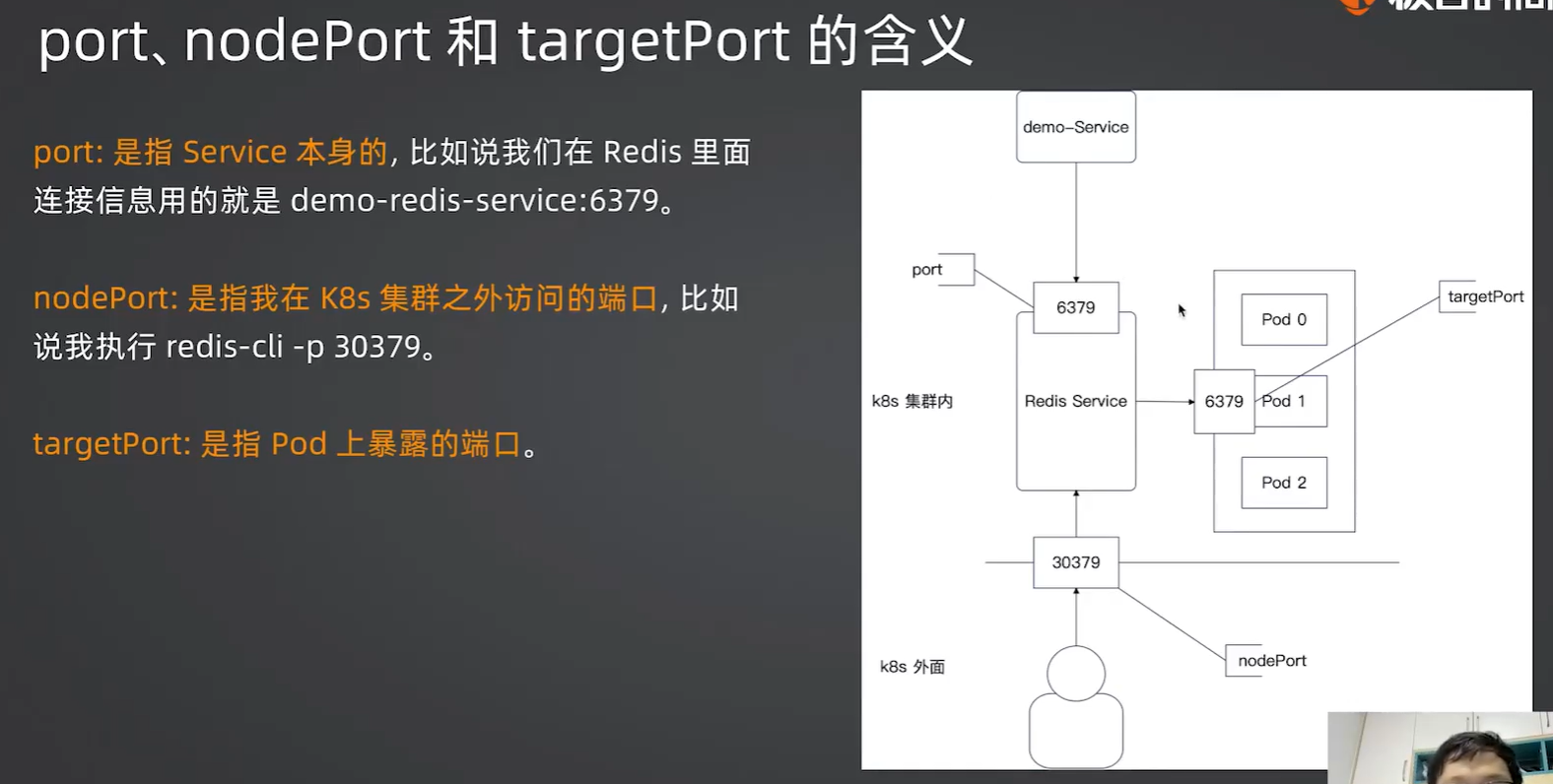
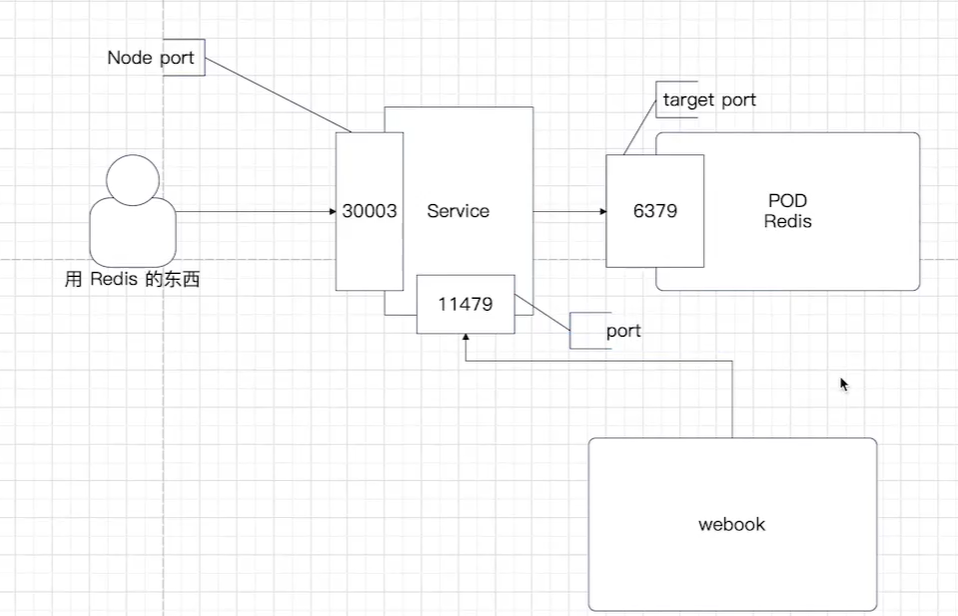
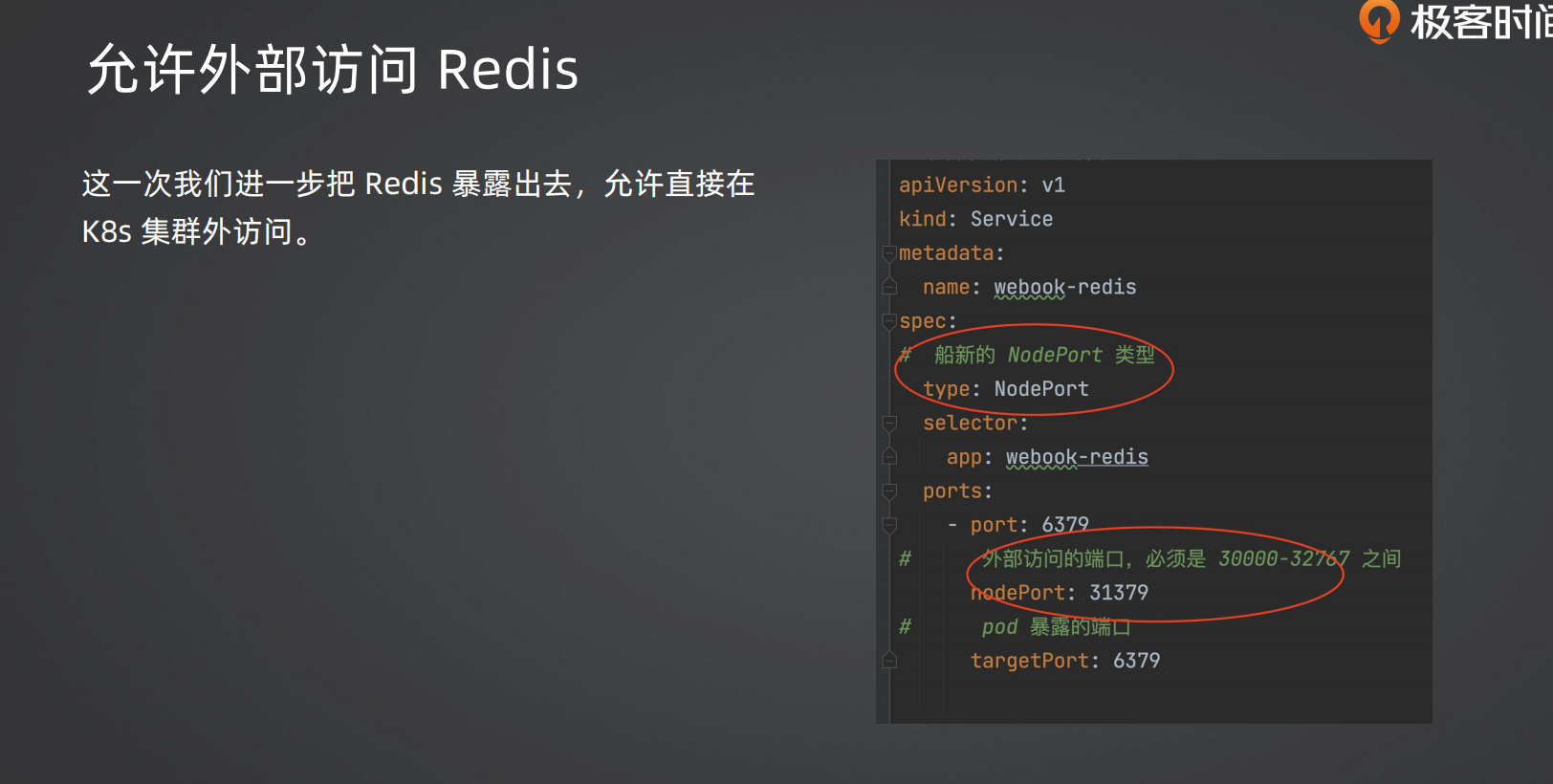
port、nodePort 和 targetPort 的区别
| 端口类型 | 是谁的端口 | 在哪里用 | Redis 配置值 |
|---|---|---|---|
port |
Service 自己的端口 | K8s 集群内部访问时使用(比如一个 Pod 访问另一个 Service) | 11479 |
nodePort |
K8s 节点(虚拟机/宿主机)的端口 | K8s 集群外部访问时使用(比如你电脑上的 redis-cli) |
30003 |
targetPort |
Pod 内容器监听的端口 | Service 把流量转给 Pod 时,发到 Pod 的这个端口 | 6379 |
流量走向图解(你图里的意思):
1 | 外部客户端(redis-cli) |
4.5 NodePort和 LoadBalancer
1. NodePort 和 LoadBalancer 的区别
这是 Service 的两种暴露类型,区别在于“外部怎么访问”。
| 对比维度 | NodePort | LoadBalancer |
|---|---|---|
| 访问地址 | http://<节点IP>:<nodePort> |
云厂商分配一个公网 IP(或 Docker Desktop 映射到 localhost) |
| 访问路径 | 你的电脑 → K8s 节点 IP + 端口 → Service → Pod | 你的电脑 → 负载均衡器 IP → Service → Pod |
| 在 Docker Desktop + WSL2 中的表现 | ❌ 不自动映射到 localhost,连不上 |
✅ Docker Desktop 把端口自动映射到 localhost,能直接访问 |
| 适用场景 | 本地调试(有公网/内网 IP 的情况)、小型集群 | 云服务生产环境、Docker Desktop 本地开发 |
| 端口范围 | 固定范围 30000-32767(K8s 限制) | 端口由你指定(如 6379、11479) |
2. 为什么在windows下把nodeport改 LoadBalancer 就成功了?
NodePort 方式:redis-cli -h localhost -p 30003 → 请求到达 Windows 宿主机 → Windows 防火墙 + WSL2 网络隔离 → 请求被挡住,到不了 WSL2 虚拟机内的 NodePort。
LoadBalancer 方式(Docker Desktop 特殊支持):redis-cli -h localhost -p 11479 → 请求到达 Windows 宿主机 → Docker Desktop 的负载均衡器在 Windows 的 127.0.0.1:11479 上监听 → 直接接收请求 → 内部转发给 K8s Service → 到达 Pod。
本质:LoadBalancer 在 Docker Desktop 中绕过了 WSL2 的网络隔离,直接在 Windows 宿主机上开了“门”。
port是 Service 对内的门牌号,targetPort是 Pod 的门牌号,nodePort是外部门牌号但受防火墙限制。
在 Docker Desktop 下,LoadBalancer相当于把门直接开在 Windows 的localhost上,所以能直接访问。NodePort的门开在 WSL2 虚拟机里,Windows 过不去。
五、K8s 部署 nginx
5.1 为什么需要 Ingress?
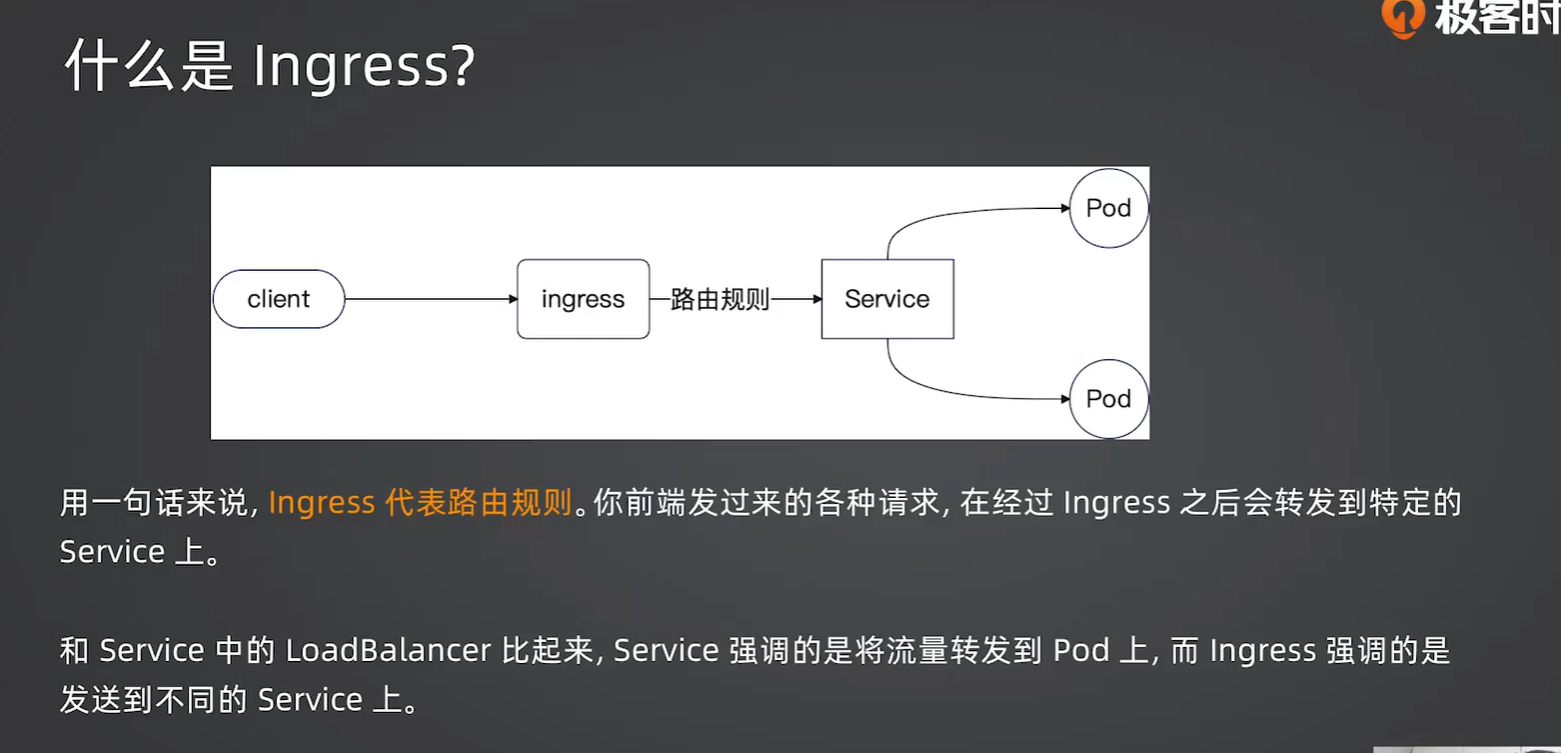
Service(LoadBalancer)是四层负载均衡。所谓”四层”,就是它只工作在传输层,能看懂 IP 地址和端口号,但看不懂 HTTP 请求的具体内容(比如路径 /api 或 /hello)。所以它转发流量时是”盲转”——来了什么就转什么,不做路由判断。这就导致一个 Service 只能对应一个端口/IP,如果你有十个服务需要暴露,就得配十个 LoadBalancer,每个占用一个端口或公网 IP,浪费资源且难以管理。
Ingress 是七层路由。”七层”指的是应用层,它能看懂 HTTP 请求里的域名(live.webook.com)和路径(/api、/admin),并据此做智能路由。因此多个 Service 可以共用一个统一入口,由 Ingress 根据请求内容分发给不同的后端。
1 | 用户 → Ingress(一个入口) |
补充:Ingress 定义的只是路由规则,真正执行转发的是 Ingress Controller(
ingress-nginx)。规则 + 执行者,缺一不可。
5.2 Ingress 依赖 Ingress Controller
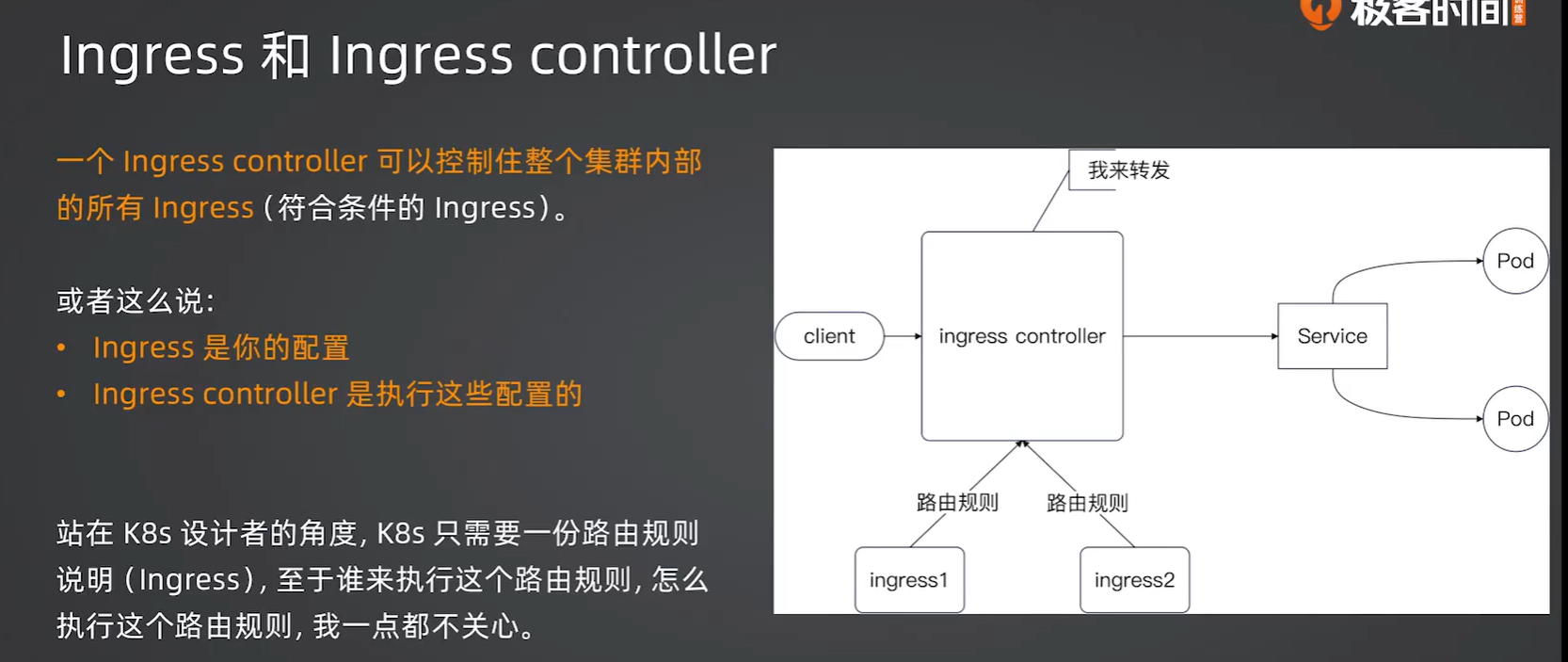
其实就是 ingress是制定规则(定好路由规则),ingress controller是执行规则(按照这些路由规则去分发数据),比如ingress规定了A发的就要往B发,C发的就要往D走,那么A真的过来了,就是ingress controller根据这个规则把A发的发到B去了
5.3 安装ingress并验证
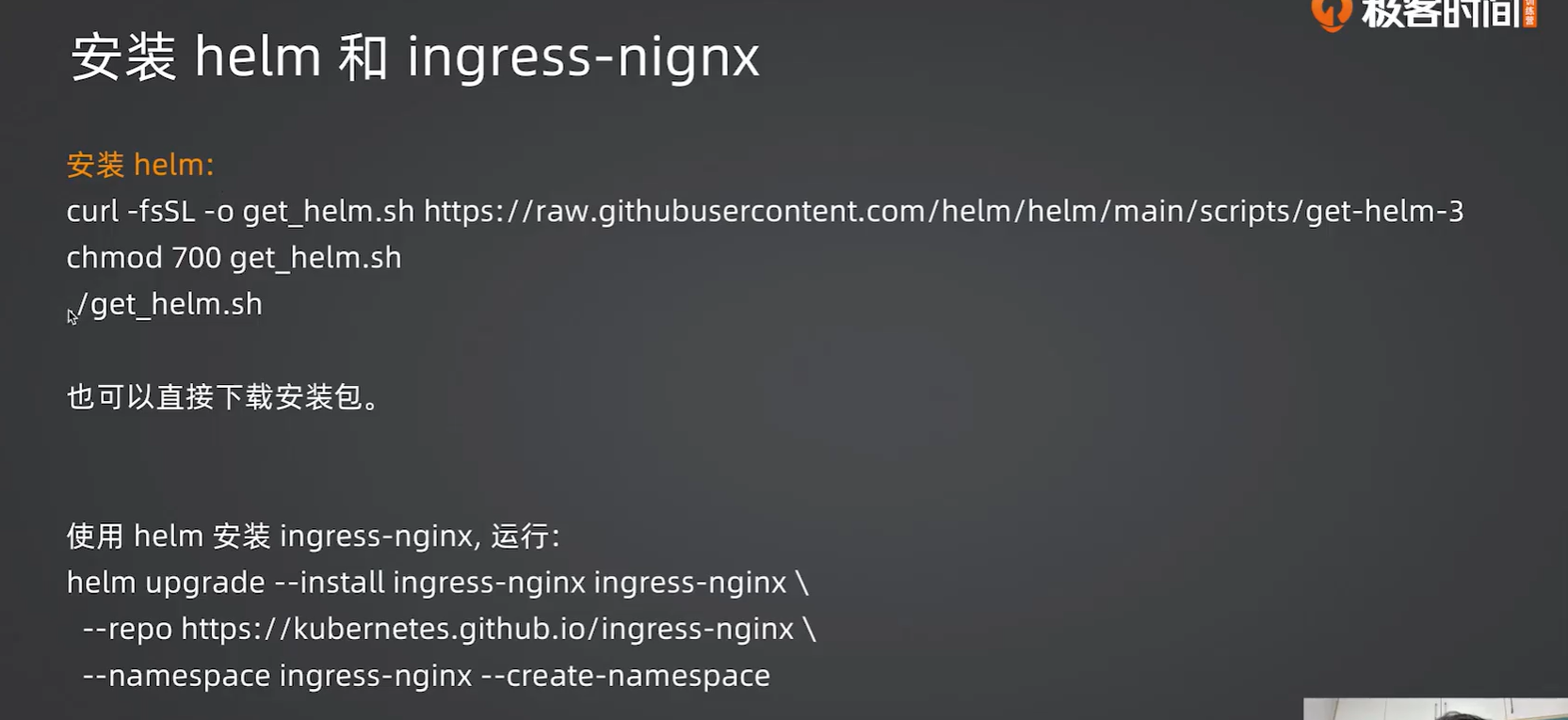
命令都需要在git bash中执行,并且需要科学上网
1 | curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 |
据笔者个人尝试,windows下没办法弄第一条命令,只能手动安装
直接打开https://github.com/helm/helm/releases这个网址,下载好之后解压把它放到自己想要的目录,比如我就是放到g/heml下了,然后在环境变量中添加heml.exe所在目录
然后去git bash中输入
1 | helm version |
得到以下输出代表成功安装
1 | version.BuildInfo{Version:"v3.21.2", GitCommit:"125963406833fe0525be91f46c8b5b0f22fb9e32", GitTreeState:"clean", GoVersion:"go1.26.4"} |
执行下面的命令
1 | helm upgrade --install ingress-nginx ingress-nginx \ |
得到以下输出算是成功
1 | Release "ingress-nginx" has been upgraded. Happy Helming! |
可以通过如下命令验证
1 | #看 Pod 的状态(最重要) |
看 Pod 的状态
1 | kubectl get pods -n ingress-nginx -w |
- 耐心看几行,如果状态最终变为
Running(且READY变成1/1),说明容器跑起来了。 - 如果长时间
Pending或ContainerCreating,说明在拉取镜像,多等一会儿。
看 Service 是否分配了外部 IP
1 | kubectl get svc -n ingress-nginx |
会看到一个叫 ingress-nginx-controller 的 Service,类型是 LoadBalancer。它的 EXTERNAL-IP 列:
- 一开始显示
<pending>,这是正常的。 - 等一两分钟后,如果变成
localhost或127.0.0.1,说明大功告成了,你现在可以通过localhost访问它来做路由转发。
ingress-nginx
ingress-nginx 这个控制器里,主要包含 两大组件:一个控制器(Controller) 和 Nginx 本身。也就是说ingress-nginx和nginx是包含关系
我们可以把它理解为一个紧密协作的“大脑”和“执行者”的组合:
- 控制器 (Controller):这是整个控制器的“大脑”。它是一个用 Go 语言编写的程序,职责是与 Kubernetes API 服务器通信,实时监控集群中
Ingress、Service等资源的变化。一旦发现你创建或修改了Ingress规则,它就会立刻生成一份新的 Nginx 配置文件(nginx.conf)。 - Nginx:这是实际处理流量的“执行者”。它是一个高性能的 Web 服务器和反向代理。它的工作就是根据控制器生成的
nginx.conf配置文件,接收外部请求并将其转发到你定义的后端服务上。
它们俩就像一对配合默契的搭档,共同在同一个 Pod 里工作:
- 感知变化:控制器(大脑)时刻盯着 Kubernetes 的 API 服务器。
- 生成配置:当你创建或更新
Ingress规则时,大脑立刻行动,根据规则生成一份新的 Nginx 配置文件。 - 更新执行:大脑将新配置传递给 Nginx(执行者),并让它优雅地重新加载配置。这个过程保证了服务不中断。
- 处理请求:从此以后,所有进入集群的外部请求,都会由这个时刻准备着的 Nginx 执行者,按照最新配置进行路由和转发。
5.4 ingress.yaml

1 | apiVersion: networking.k8s.io/v1 |
注意service部分的name和port要和ks8-webook-service.yaml里面的对应上
5.5 验证
1.配置hosts文件
按
Win + S,搜索 “记事本”。右键点击“记事本”,选择 “以管理员身份运行”。
在记事本里,点击 文件 → 打开。
导航到
C:\Windows\System32\drivers\etc\目录。右下角文件类型从
.txt改成 “所有文件”。选择
hosts文件,点击打开。在文件末尾另起一行,添加:
1
127.0.0.1 live.webook.com
保存文件(Ctrl + S),然后关闭记事本
加这行 127.0.0.1 live.webook.com,本质上是在“本地 DNS 解析”这一步做了个手脚,绕过了公网 DNS 服务器。因为 live.webook.com 这个域名是虚构的,并没有在阿里云、Cloudflare 等公网 DNS 服务商那里注册过。
如果不加这一行,浏览器访问 http://live.webook.com 时会发生:
- 浏览器问 DNS 服务器:“
live.webook.com这个网站的 IP 是多少?” - DNS 服务器在全球查了一圈,发现:这个域名不存在,没注册过。
- 浏览器找不到这个网站! 直接报
ERR_NAME_NOT_RESOLVED,连电脑的网卡都出不去。
结果就是:根本碰不到 ingress-nginx,更别提什么路由规则了。
加了 127.0.0.1 live.webook.com 之后发生了什么?
- 浏览器问 DNS 之前,先查本地的
hosts文件。它发现:live.webook.com对应127.0.0.1。 - 浏览器直接告诉你:“这网站就在你自己电脑上(
127.0.0.1)。” - 请求直接打到本机的 80 端口,正好被
ingress-nginxController 接住(它已经在本地 80 端口监听了)。 ingress-nginx收到请求,看到请求头里的Host: live.webook.com,和你写的 Ingress 规则里的host: live.webook.com匹配上了,于是按规则转发。
2. 访问对应网站出现以下结果说明配置成功
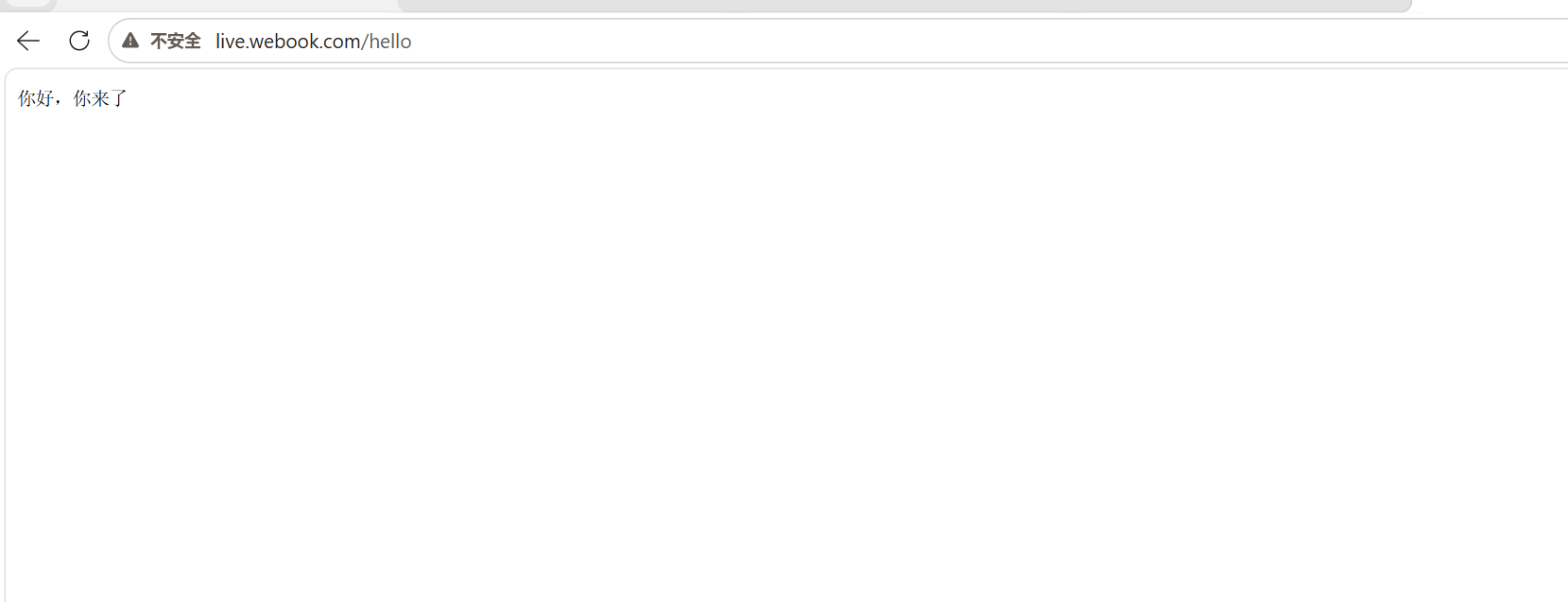
1 | 浏览器访问 http://live.webook.com/hello |
六、集成mysql和redis
1.修改代码
把之前注释的代码都打开
1 | func main() { |
1 | //main.go的initDB函数的的下面这行 |
1 | //同理对redis进行修改 第5行和第21行,记得都要改,只改一个不行 |
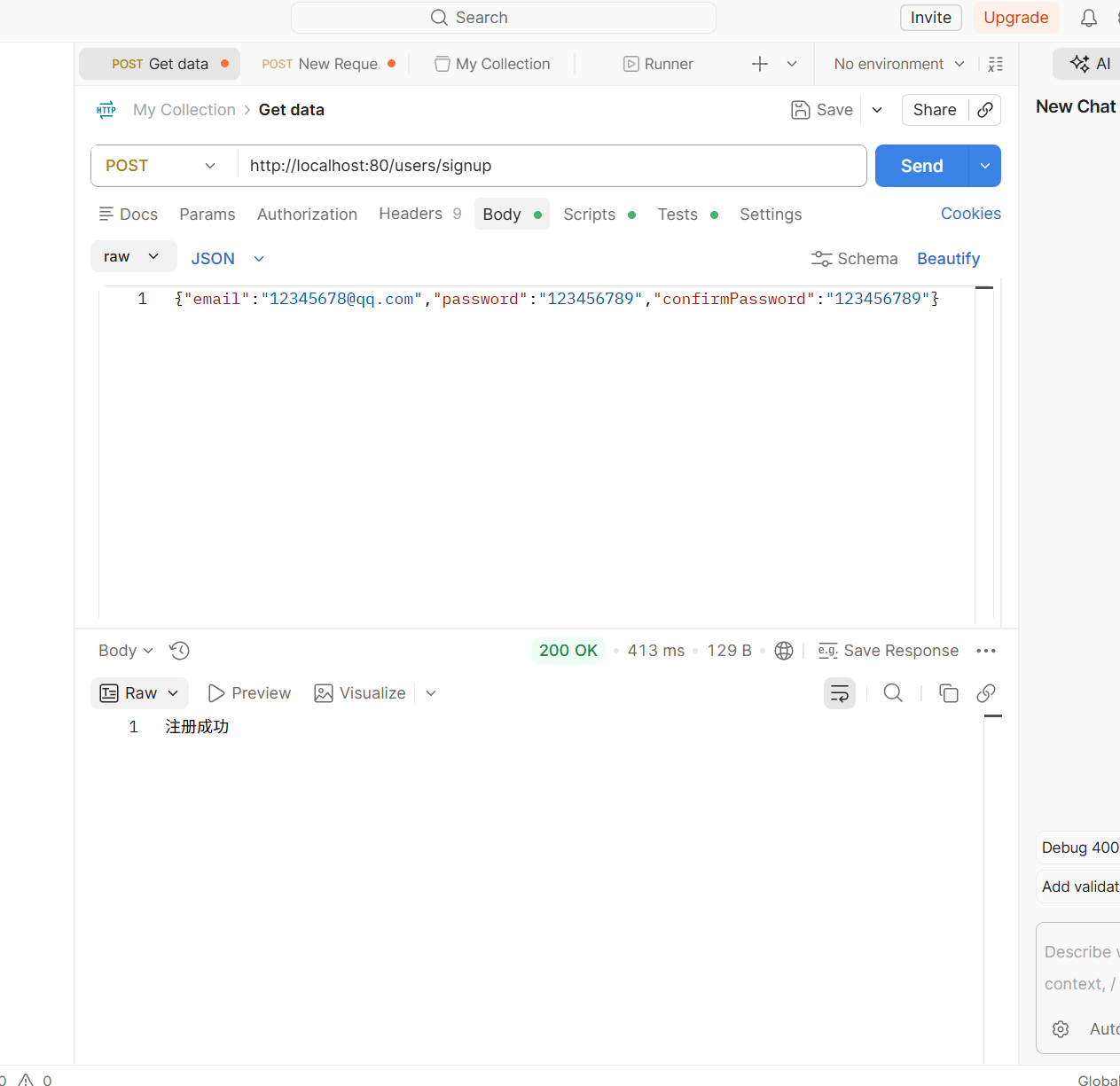
2.验证
1 | make docker |
如果你发现下面两个不能访问,但是live.webook.com/hello还可以访问,那只能说明还是旧的镜像
3.小技巧


1 | //dev.go |
1 | //k8s.go |
1 | package config |
1 | //main.go 中的修改 一共修改下面三个地方,替换成上面配置文件中的东西即可 |
1 | //makefile修改 下面这行加入tags参数 |
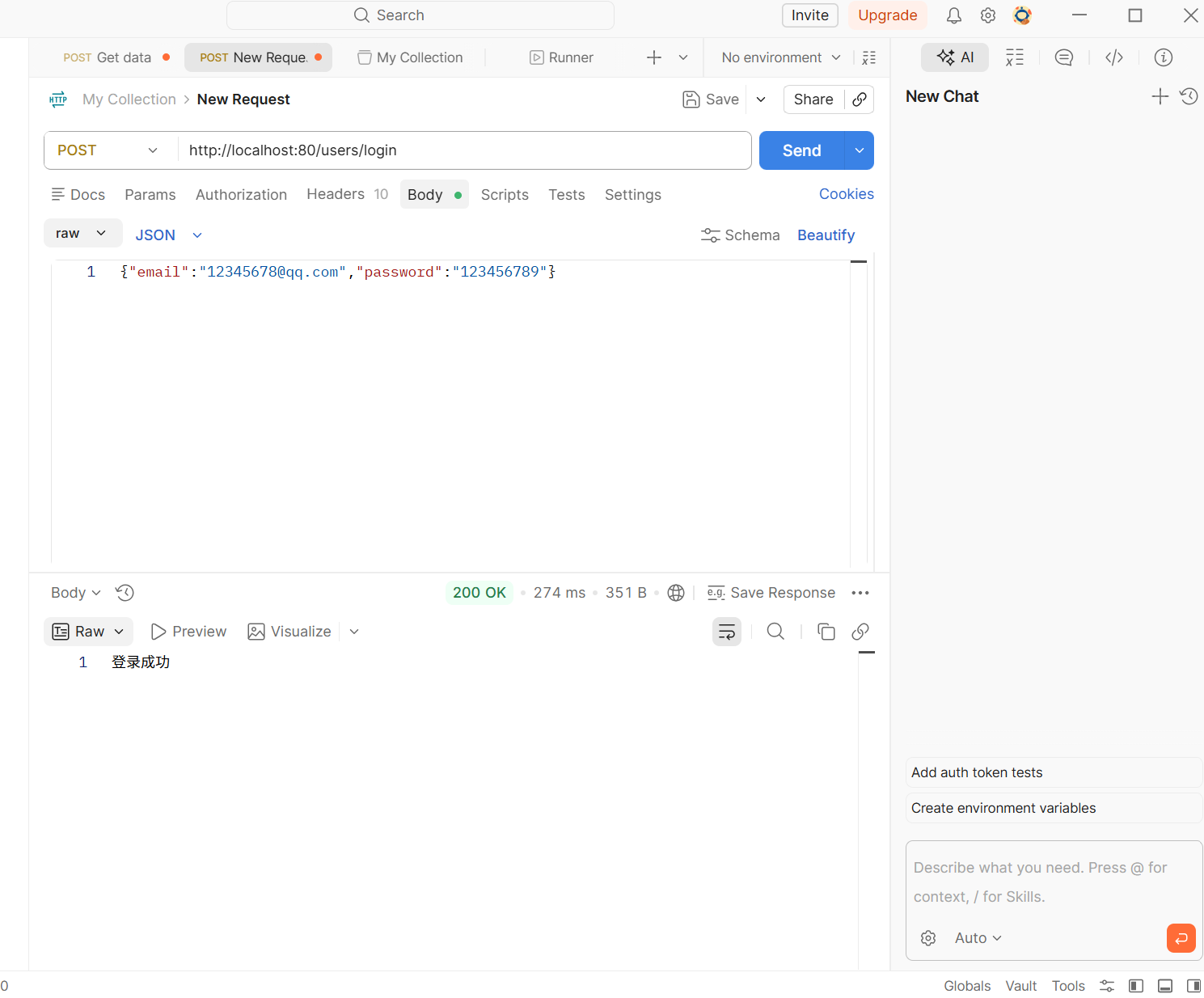
之后还是执行这三条命令,然后去postman访问那两个页面看看是不是成功了
1 | make docker |
4.在浏览器中访问
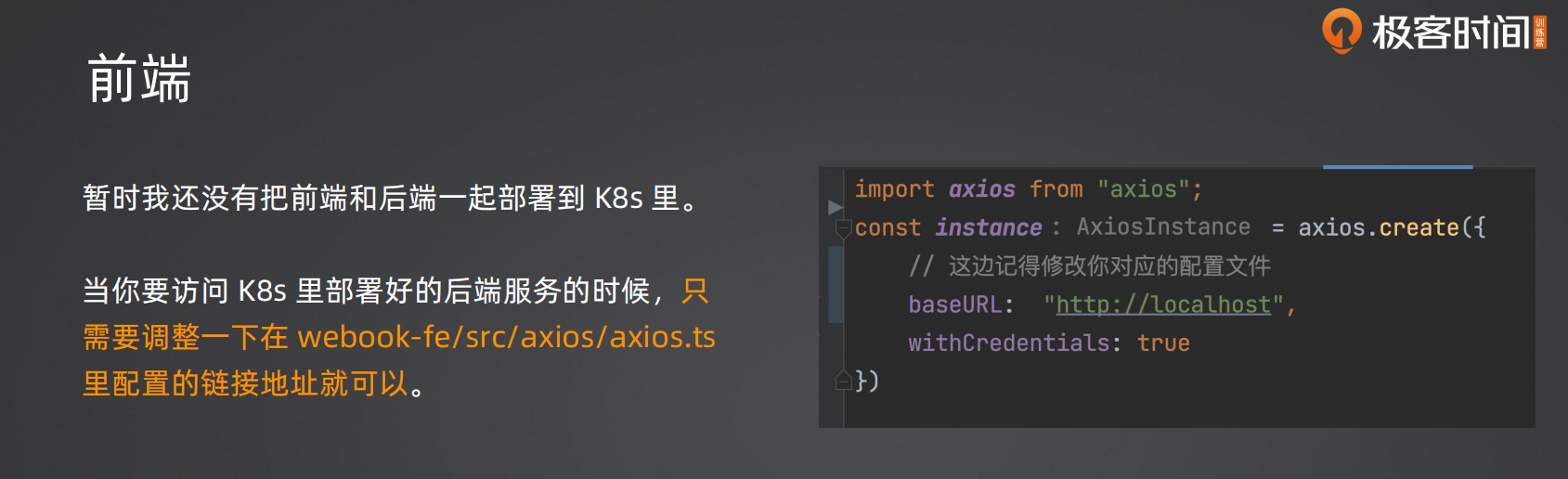
1 | const instance = axios.create({ |
把9090换成80后,去webook-fe目录下输入npm run dev然后就可以正常访问登录注册页面和功能了
最后去mysql-k8s数据库中查一下是不是已经有了具体的数据,有了就代表全都通顺了
注:
浏览器直接访问 live.webook.com/users/signup
浏览器地址栏发的是 GET 请求,但后端 user.go 里注册的是:
1 | server.POST("/users/signup", u.SignUp) // ← 只有 POST |
Gin 找不到 GET /users/signup,返回 404。
而通过前端 localhost:3000/users/signup 注册登录
前端的 axios.ts 里:
1 | baseURL: "http://localhost:80", // ← 直接连 K8s LoadBalancer Service |
表单提交时 axios 发的是 POST 请求,路由匹配 POST /users/signup,一切正常。而且前端走的是 localhost:80(Docker Desktop 直接把 LoadBalancer 映射到了本地),根本没经过 Ingress。
总结
live.webook.com/users/signup |
localhost:3000 前端 |
|
|---|---|---|
| 请求方式 | GET(浏览器地址栏) | POST(axios) |
| 后端匹配 | ❌ 无 GET 路由 → 404 | ✅ POST /users/signup → 成功 |
| 流量路径 | Ingress → Service | 直接 LoadBalancer:80 |
**live.webook.com 是后端 API,不是给人”看”的。要使用它只能用 Postman(发 POST)或者让 axios 的 baseURL 指向它。**浏览器直接访问它没有意义——就好比你用浏览器访问 https://api.github.com/users 能看到 JSON,但你访问 live.webook.com 没有根路由就什么都没有。
七、作业

 微信
微信 支付宝
支付宝






